How To Set Up a Multi-Node Kafka Cluster using KRaft
kafka node #1,2,3 별로 아래의 링크에 따라 kafka를 설치합니다.
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz
tar xvzf kafka_2.13-3.8.0.tgz
mv kafka_2.13-3.8.0 kafka
cd kafka
bin/kafka-storage.sh random-uuid
# or
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties


Step 1 - Configuring Kafka Nodes
세 개의 Kafka 서버가 동일한 KRaft 클러스터의 일부가 되도록 구성합니다. KRaft를 사용하면 노드 자체에서 관리 작업을 구성하고 수행할 수 있으므로 Apache ZooKeeper에 의존하는 오버헤드 없이도 관리 작업을 수행할 수 있습니다.
이 세 가지 매개변수는 Kafka 노드가 브로커와 컨트롤러의 역할을 모두 수행하도록 구성하며, 즉 데이터를 수신 및 소비(브로커)하고 관리 작업(컨트롤러)을 수행합니다. 이러한 분리는 컨트롤러를 분리하여 효율성과 중복성을 높일 수 있는 대규모 배포에 유용합니다.
vi config/kraft/server.properties
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9092
node.id는 클러스터에서 노드의 ID를 지정합니다. 이것은 첫 번째 노드이므로 1로 남겨 두어야 합니다. 모든 노드는 고유한 노드 ID를 가져야 하므로 두 번째 및 세 번째 노드는 각각 2와 3의 ID를 갖게 됩니다.
controller.quorum.voters는 노드 ID를 각각의 주소와 통신을 위한 포트에 매핑합니다. 여기에서 모든 클러스터 노드의 주소를 지정하여 각 노드가 다른 노드를 모두 인식할 수 있도록 합니다. 줄을 다음과 같이 수정합니다:
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@kafka1.mydomain.com:9093,2@kafka2.mydomain.com:9093,3@kafka3.mydomain.com:9093
여기에는 클러스터의 세 노드를 모두 각각의 ID와 함께 나열합니다. mydomain.com을 자신의 도메인으로 설정한 도메인 주소로 바꾸는 것을 잊지 마세요.
listeners=PLAINTEXT://kafka1:9092,CONTROLLER://kafka1:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://kafka1.mydomain.com:9092
설명에 나와 있듯이 이렇게 하면 각 새 토픽의 기본 파티션 수가 구성됩니다. 노드가 3개이므로 2의 배수로 설정합니다:
num.partitions=6
다음으로, 소비자(Consumer) 오프셋(Offsets)과 트랜잭션 상태를 유지하는 내부 토픽에 대한 복제 인자를 구성합니다. 다음 줄을 찾습니다:
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
여기에서는 내부 메타데이터와 관련하여 최소 두 개의 노드가 동기화되어야 한다고 지정합니다. 완료했으면 파일을 저장하고 닫습니다.
기본 파티션 번호를 설정한 후에는 로그 저장소를 다시 초기화해야 합니다. 먼저 실행을 통해 기존 로그 파일을 삭제합니다:
그런 다음 새 클러스터 ID를 생성하고 환경 변수에 저장합니다:
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
echo $KAFKA_CLUSTER_ID
출력 예시
L5PYZLFDQZGPtCwp-Yj2lg
두 번째 및 세 번째 노드를 구성하는 데 필요한 값이므로 이 값을 메모해 두세요.
마지막으로 다음 명령을 실행하여 로그 저장소를 생성합니다:
./bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
출력 예시
Formatting /tmp/kraft-combined-logs with metadata.version 3.8-IV0
Configuring 2,3 Node
다른 노드를 구성하는 것은 첫 번째 노드에 대해 방금 수행한 작업과 매우 유사합니다. node.id도 업데이트해야 한다는 점에 유의하세요:
vi config/kraft/server.properties
node.id=node_number
두 번째 및 세 번째 노드에 적절한 값은 각각 2와 3이며, 청취자 및 advertised.listeners에 적절한 주소를 설정합니다.
로그 저장소를 다시 생성할 때는 첫 번째 노드의 클러스터 ID 를 재사용하세요:
첫 번째 노드의 클러스터 ID : L5PYZLFDQZGPtCwp-Yj2lg
두번째 노드의 클러스터 ID : KAFKA_CLUSTER_ID=”L5PYZLFDQZGPtCwp-Yj2lg”
세번째 노드의 클러스터 ID : KAFKA_CLUSTER_ID=”L5PYZLFDQZGPtCwp-Yj2lg”
Step 2 - Connecting to the Cluster
이 단계에서는 Kafka와 함께 번들로 제공되는 셸 스크립트를 사용해 Kafka 클러스터에 연결합니다. 또한 토픽을 생성하고 클러스터에서 데이터를 생성 및 소비해 봅니다. 그런 다음 노드 중 하나를 다운시키고 Kafka가 손실을 완화하는 방법을 관찰합니다.
Kafka는 클러스터와 그 구성원에 대한 정보를 보여주는 kafka-metadata-quorum.sh 스크립트를 제공합니다. 다음 명령을 실행하여 실행하세요:
./bin/kafka-metadata-quorum.sh --bootstrap-controller kafka1.mydomain.com:9093 describe --status
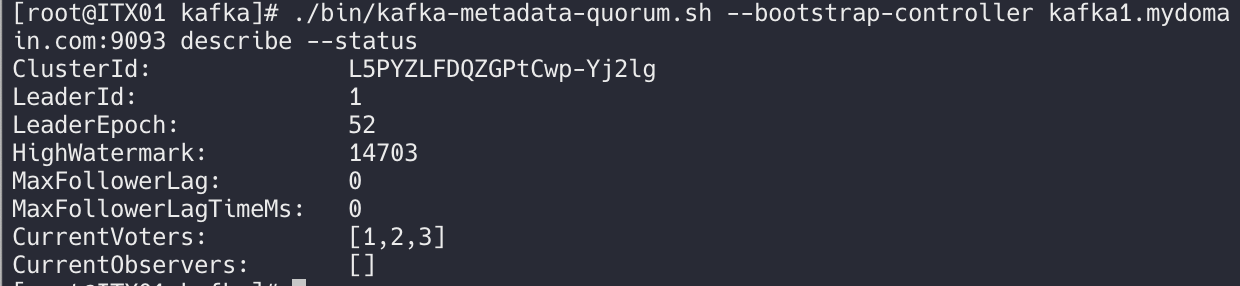
이 스크립트는 클러스터 상태에 대한 기본 정보를 나열합니다. 표시된 출력에서 노드 1이 리더로 선출되고 세 노드([1,2,3])가 모두 투표 풀에 있으며 해당 결정에 동의하는 것을 볼 수 있습니다.
Step 3 - 토픽 생성
실행하여 첫 번째 토픽이라는 토픽을 만듭니다:
./bin/kafka-topics.sh --create --topic first-topic --bootstrap-server kafka1:9092 --replication-factor 2
그런 다음 kafka-topics.sh 스크립트를 실행하여 노드에서 파티션이 어떻게 배열되어 있는지 확인합니다:
./bin/kafka-topics.sh --describe --bootstrap-server kafka1:9092 --topic first-topic
OutputTopic: first-topic TopicId: 4kVImoFNTQeyk3r2zQbdvw PartitionCount: 6 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: first-topic Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: first-topic Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: first-topic Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: first-topic Partition: 3 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: first-topic Partition: 4 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: first-topic Partition: 5 Leader: 2 Replicas: 2,1 Isr: 2,1
각 파티션에는 리더, 복제본 2개, 동기화 복제본 세트(ISR) 2개가 있는 것을 볼 수 있습니다. 파티션 리더는 파티션 데이터를 클라이언트에 제공하는 브로커 노드이며, 복제본은 사본만 보관합니다. 복제 노드는 기본적으로 지난 10초 동안 리더 노드를 따라잡은 경우 ISR로 간주됩니다. 이 시간 간격은 토픽별로 구성할 수 있습니다.
Step 4 - Producer 메시지 생성
이제 토픽을 만들었으므로 kafka-console-producer.sh 스크립트를 사용하여 해당 메시지를 생성합니다. 다음 명령을 실행하여 프로듀서를 시작합니다:
./bin/kafka-console-producer.sh --topic first-topic --bootstrap-server kafka1:9092


Step 5 - Consumer 메시지 수신
이제 프로듀서는 다음 메시지를 기다리고 있으며, 이는 이전 메시지가 카프카에 성공적으로 전달되었음을 의미합니다. 테스트를 위해 원하는 만큼 메시지를 입력할 수 있습니다. 프로바이더를 종료하려면 CTRL+C를 누릅니다.
토픽의 메시지를 다시 읽으려면 소비자가 필요합니다. Kafka는 kafka-console-consumer.sh로 간단한 소비자를 제공합니다. 실행하여 실행하세요:
./bin/kafka-console-consumer.sh --topic first-topic --from-beginning --bootstrap-server kafka1:9092

final - server.properties
node 1의 server.properties에서 수정한 부분입니다.
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@kafka1.mydomain.com:9093,2@kafka2.mydomain.com:9093,3@kafka3.mydomain.com:9093
# The address the socket server listens on.
listeners=PLAINTEXT://kafka1:9092,CONTROLLER://kafka1:9093
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://kafka1.mydomain.com:9092
num.partitions=6
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
node 2의 server.properties에서 수정한 부분입니다.
# The node id associated with this instance's roles
node.id=2
# The connect string for the controller quorum
controller.quorum.voters=1@kafka1.mydomain.com:9093,2@kafka2.mydomain.com:9093,3@kafka3.mydomain.com:9093
# listeners=PLAINTEXT://:9092,CONTROLLER://:9093
listeners=PLAINTEXT://kafka2:9092,CONTROLLER://kafka2:9093
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://kafka2.mydomain.com:9092
num.partitions=6
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
node 3의 server.properties에서 수정한 부분입니다.
# The node id associated with this instance's roles
node.id=3
# The connect string for the controller quorum
controller.quorum.voters=1@kafka1.mydomain.com:9093,2@kafka2.mydomain.com:9093,3@kafka3.mydomain.com:9093
# The address the socket server listens on.
listeners=PLAINTEXT://kafka3:9092,CONTROLLER://kafka3:9093
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://kafka3.mydomain.com:9092
num.partitions=6
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
댓글남기기