kafkacat 사용법
카프카캣은 kafka producer/consumer 도구이며, 카프카캣을 얼마나 쉽게 사용할 수 있는지, 그리고 카프카캣으로 어떤 멋진 일을 할 수 있는지 설명 합니다.
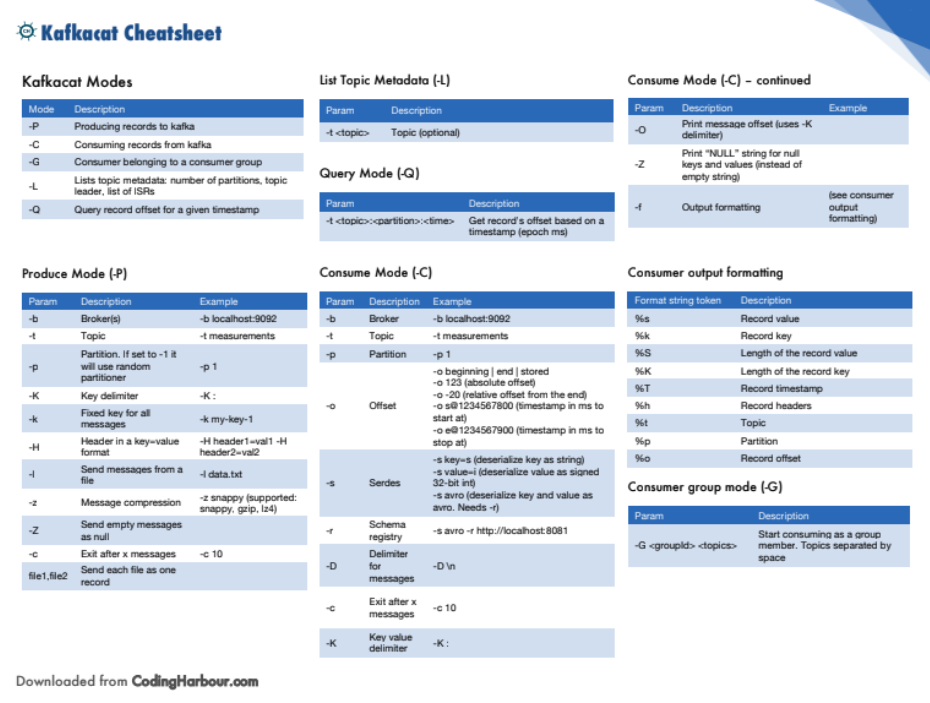
카프카캣은 카프카 메시지를 생성하고 소비하기 위한 명령줄 도구입니다. 또한 클러스터 또는 토픽에 대한 메타데이터를 볼 수 있습니다.
카프카캣에는 꽤 많은 매개변수가 있어 모두 익히는 것이 무섭게 느껴질 수도 있지만, 대부분의 매개변수는 의미가 있고 기억하기 쉽습니다. 가장 중요한 모드부터 시작하겠습니다. 카프카캣으로 전화를 걸 때는 항상 네 가지 모드 중 하나를 사용하게 됩니다. 모든 모드는 대문자를 사용합니다:
docker run --tty \
--network host \
confluentinc/cp-kafkacat \
kafkacat -b kafka:9092 -C -K: \
-f '\nKey (%K bytes): %k\t\nValue (%S bytes): %s\n\Partition: %p\tOffset: %o\n--\n' \
-t testuser01
- -P = Produce data
- -C = Consume data
- -L = List metadata
- -Q = Query
그 다음으로 중요한 옵션은 브로커 목록(-b)이며, 그 다음에는 보통 토픽(-t)입니다.
따라서 명령어를 거의 이야기처럼 작성할 수 있습니다. 다음 명령은 다음과 같습니다:
kafkacat -C -b localhost:9092 -t testuser01 -o beginning
로 읽을 수 있습니다: 오프셋이 처음에 설정된 브로커 localhost:9092 및 topic topic1에서 소비하고 싶습니다.
이제 이 모든 암호화된 매개변수가 의미가 있다는 것을 확신하셨으면 좋겠고, 이제 Kafkacat을 사용하여 몇 가지 일반적인 작업을 수행하는 방법을 살펴봅시다.
Producing data (-P)
데이터를 생산하려면 무엇이 필요할까요? 최소한 브로커와 작성하려는 토픽이 필요합니다.
Produce values
kafkacat -P -b localhost:9092 -t testuser01
키가 포함된 메시지를 생성하려면 키 구분 기호(-K)를 지정해야 합니다. 콜론을 사용하여 입력에서 키와 메시지를 구분해 보겠습니다:
kafkacat -P -b localhost:9092 -t testuser01 -K :
key3:message3
key4:message4
이 매개변수는 대문자 K를 사용합니다.
Produce messages with headers 메시지에 헤더를 추가하려면 -H 매개변수를 사용하여 키=값 형식으로 헤더를 추가합니다:
kafkacat -P -b localhost:9092 \
-t testuser01 \
-H appName=kafkacat -H appId=1
보시다시피 -H 플래그를 반복하면 추가 헤더가 추가됩니다. 생성되는 모든 메시지에는 -H 플래그가 지정된 두 개의 헤더가 있습니다.
Produce data from a file
파일을 사용하여 데이터를 생성하려면 -l(파일에서와 같이) 옵션을 사용하세요…
대부분의 매개 변수는 기억하기 쉽다고 말씀드렸잖아요 :).
콜론으로 구분된 키-값 쌍이 포함된 data.txt라는 파일이 있다고 가정해 보겠습니다:
key1:message1
key2:message2
key3:message3
따라서 명령은 다음과 같습니다:
kafkacat -P -b localhost:9092 -t testuser01 -K: -l data.txt
압축된 메시지 생성
(-z) 매개변수를 사용하여 메시지 압축을 지정할 수 있습니다.
kafkacat -P -b localhost:9092 -t testuser01 -z snappy
지원되는 값은 snappy, gzip 및 lz4입니다.
Consuming data (-C)
토픽의 모든 메시지 소비하기
kafkacat -C -b localhost:9092 -t testuser01
kafka-console-consumer와 달리 kafkacat은 기본적으로 토픽의 시작 부분부터 메시지를 소비한다는 점에 유의하세요. 이 접근 방식이 저에게는 더 합리적이지만 YMMV입니다.
Consume X messages 카운트 매개변수(-c, 소문자)를 사용하여 소비할 메시지 수를 제어할 수 있습니다.
kafkacat -C -b localhost:9092 -t testuser01 -c 5
or
docker run -it --network host edenhill/kafkacat:1.5.0 \
-b kafka:9092 \
-t testuser01 \
-C -c 5
Consuming from an offset 특정 오프셋에서 데이터를 읽으려면 -o 매개변수를 사용하면 됩니다. 오프셋 매개변수는 매우 다양하게 사용할 수 있습니다. 할 수 있습니다:
Consume messages from the beginning or end
kafkacat -C -b localhost:9092 -t testuser01 -o beginning
시작 또는 끝 상수를 사용하여 카프카캣에게 소비를 시작할 위치를 알려줍니다.
kafkacat -C -b localhost:9092 -t testuser01 -o 123
오프셋에 절대값을 사용하면 Kafkacat이 지정된 오프셋부터 소비를 시작합니다. 사용할 파티션을 지정하지 않으면 Kafkacat은 지정된 오프셋의 모든 파티션을 사용합니다.
Consume last X messages in a partition(s)
kafkacat -C -b localhost:9092 -t testuser01 -o -10
docker run -it --network host edenhill/kafkacat:1.5.0 \
-b kafka:9092 \
-t testuser01 \
-C -b -o -10
음수 오프셋 값을 사용하여 이를 수행합니다.
Consume based on a timestamp 밀리초 단위로 지정된 타임스탬프 이후부터 -o s@start_timestamp 형식을 사용하여 소비를 시작할 수 있습니다. 기술적으로는 오프셋을 기준으로 소비하는 것이지만, 차이점은 제공된 타임스탬프를 기반으로 kafkacat이 오프셋을 알아낸다는 점입니다.
kafkacat -C -b localhost:9092 -t testuser01 -o s@start_timestamp
지정된 타임스탬프에 도달하면 다음을 사용하여 소비를 중지할 수도 있습니다:
kafkacat -C -b localhost:9092 -t testuser01 -o e@end_timestamp
이 기능은 발생한 오류를 디버깅할 때 오류의 타임스탬프가 있지만 메시지가 어떻게 보이는지 확인하려는 경우에 매우 유용합니다.
그런 다음 시작과 끝 오프셋을 결합하여 검색 범위를 좁힐 수 있습니다:
kafkacat -C -b localhost:9092 -t testuser01 -o s@start_timestamp -o e@end_timestamp
Formatting the output 기본적으로 카프카캣은 메시지 페이로드(카프카 레코드의 값)만 인쇄하지만, 원하는 것은 무엇이든 인쇄할 수 있습니다. 사용자 정의 출력을 정의하려면 형식에서와 같이 (-f) 플래그 뒤에 형식 문자열을 지정합니다. 다음은 메시지의 키와 값이 포함된 문자열을 인쇄하는 예제입니다:
kafkacat -C -b localhost:9092 -t topic1 \
-f 'Key is %k, and message payload is: %s \n'
k 및 %s는 형식 문자열 토큰입니다. 출력은 다음과 같을 수 있습니다:
Key is key3, and message payload is: message3
Key is key4, and message payload is: message4
다음은 문자열 형식입니다.
- Topic (%t),
- partition (%p)
- offset (%o)
- timestamp (%T)
- message key (%k)
- message value (%s)
- message headers (%h)
- key length (%K)
- value length (%S)
Producer Basic Usage Produce a Message :
kafkacat -b <broker> -t <topic> -P
-b: Specify Kafka broker(s).
-t: Specify the target topic.
-P: Enter the producer mode
다음 명령은 stdin에서 입력을 읽고 테스트 토픽에 메시지를 게시하는 kafkacat Docker 컨테이너를 만듭니다. 토픽은 사용 시 자동으로 생성됩니다.
docker run -it --network host edenhill/kafkacat:1.5.0 \
-b kafka:9092 \
-t testuser01 \
-P
docker run -it –network kafka-net edenhill/kafkacat:1.5.0
-b kafka:9092
-t testuser01
-P
Consumer
kafkacat -b <broker> -t <topic> -C
-b: Specify Kafka broker(s).
-t: Specify the target topic.
-C: Enter the consumer mode.
Consume from a Specific Offset :
kafkacat -b <broker> -t <topic> -C -o <offset>
-o: Specify the offset to start consuming from.
Message Manipulation
kafkacat -b <broker> -t <source_topic> -C | kafkacat -b <broker> -t <destination_topic> -P
Finding Messages :
kafkacat -b <broker> -t <topic> -C -o <offset> -c <message_count> -f <format_string>
-c: Specify the number of messages to consume.
-f: Define a custom format string to display messages.
Advanced Operations
Consume from the Latest Offset
kafkacat -b <broker> -t <topic> -C -o -1
-o -1: Consume from the latest offset.
Consume from the Earliest Offset
kafkacat -b <broker> -t <topic> -C -o -2
-o -2: Consume from the earliest offset.
Setting Consumer Group and Client ID
kafkacat -b <broker> -t <topic> -C -G <consumer_group> -C -C <client_id>
-G: Specify the consumer group.
-C: Specify the client ID.
댓글남기기