kafka 성능 metrics 모니터링
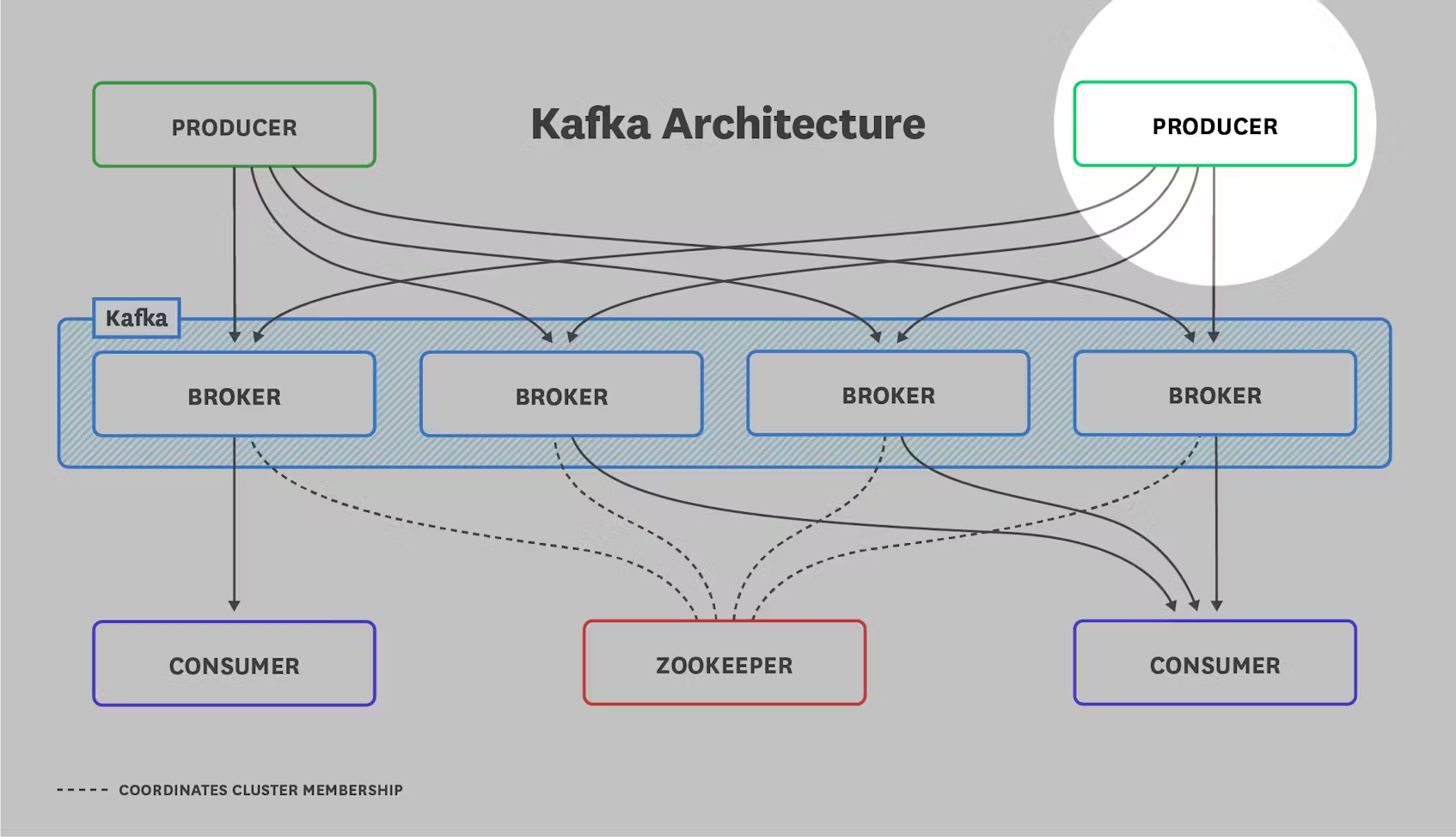
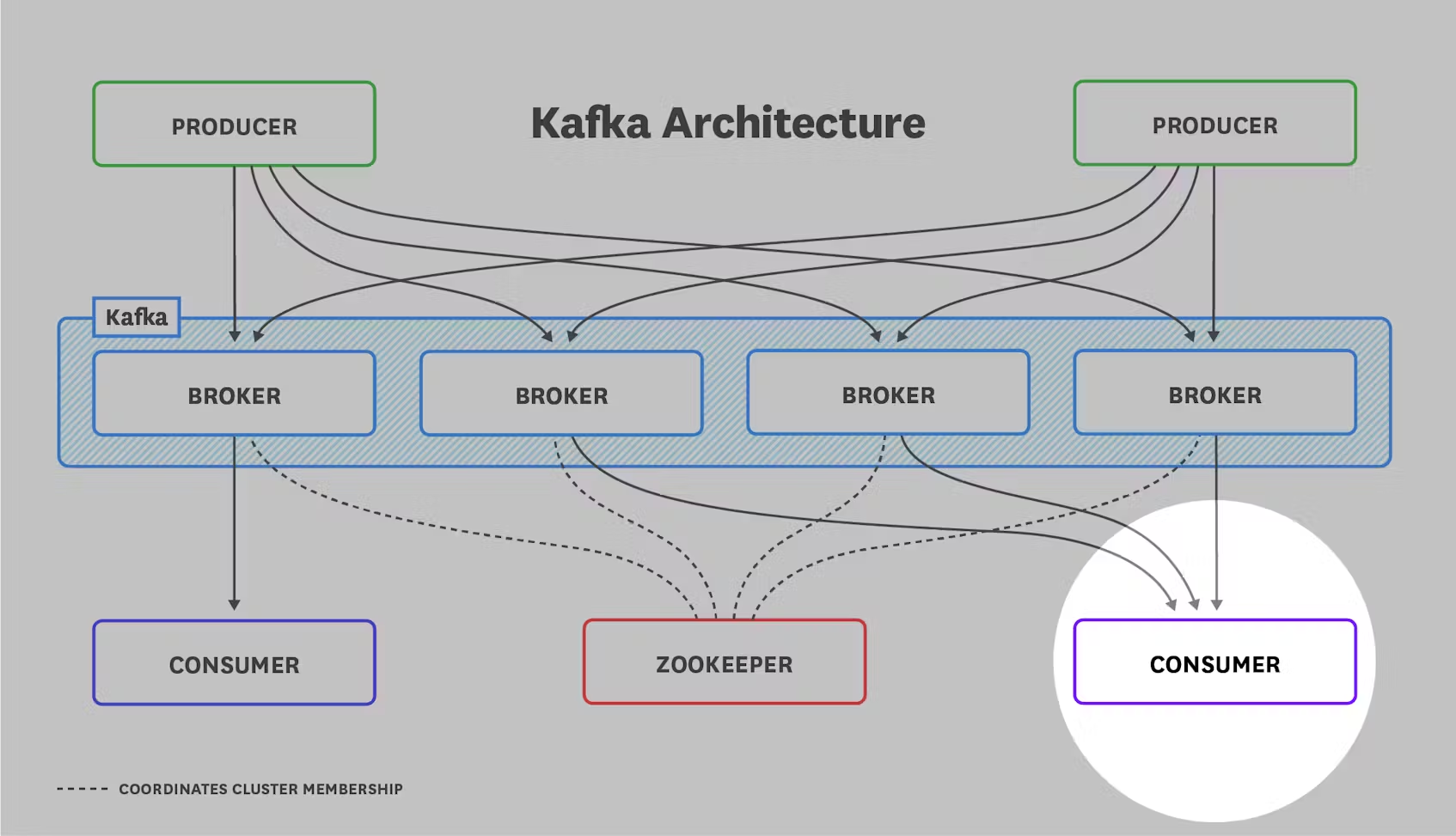
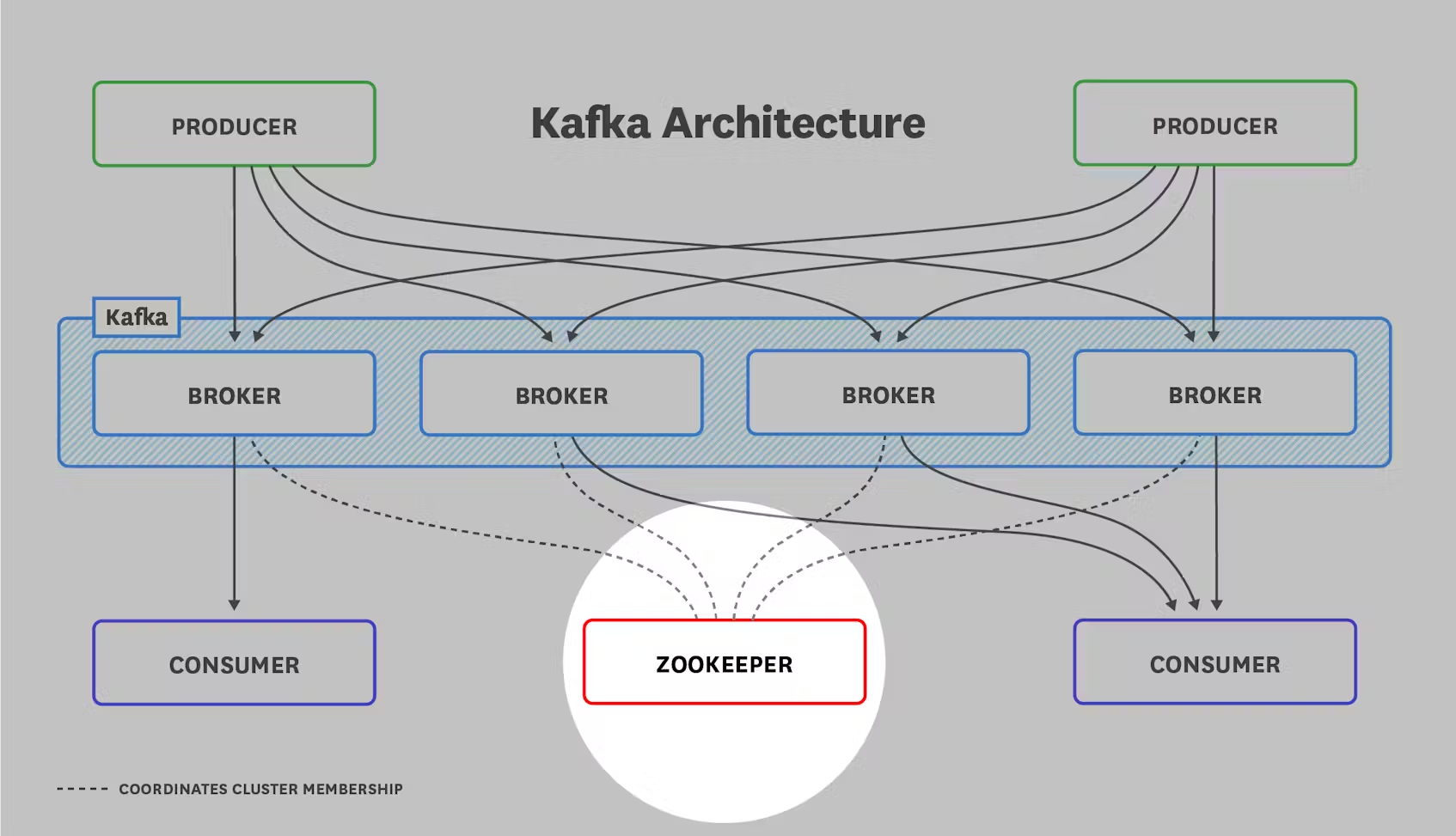
아키텍처 개요 자세히 알아보기 전에 Kafka 배포의 일반적인 아키텍처를 이해하는 것이 중요합니다. 모든 배포는 아래 그림과 같은 구성 요소로 이루어져 있습니다:
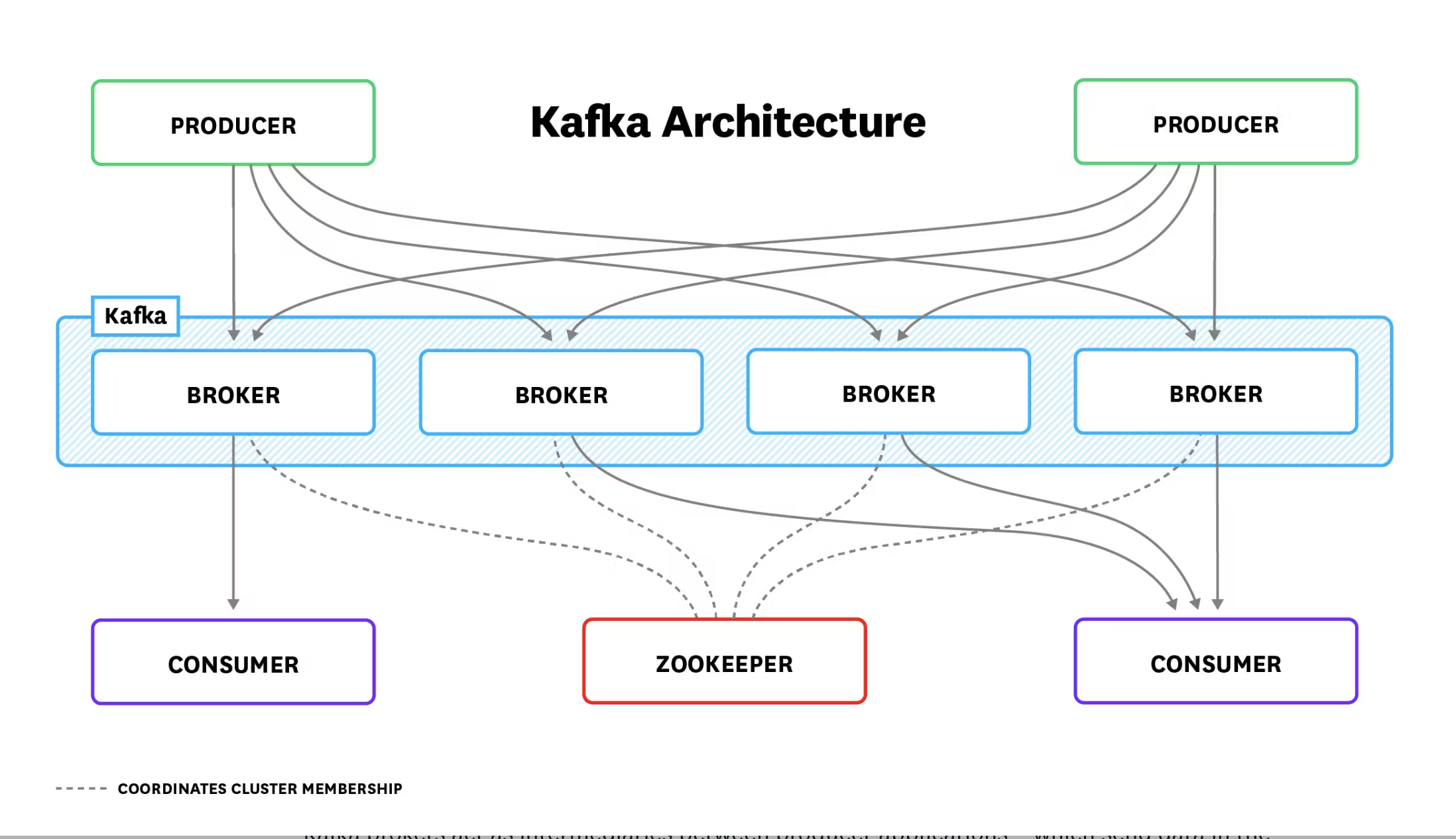
카프카 브로커는 메시지(레코드라고도 함)의 형태로 데이터를 전송하는 생산자 애플리케이션과 해당 메시지를 수신하는 소비자 애플리케이션 사이의 중개자 역할을 합니다. 생산자는 요청 횟수를 줄여 네트워크 오버헤드를 최소화하기 위해 메시지를 일괄적으로 카프카 브로커에 푸시합니다. 브로커는 소비자가 자신의 속도로 가져올 수 있도록 메시지를 저장합니다.
메시지는 메시지를 설명하는 메타데이터, 메시지 페이로드, 그리고 임의의 임의 헤더(버전 0.11.0 기준)로 구성됩니다. Kafka의 메시지는 브로커가 수신한 순서대로 로그에 기록되며, 변경할 수 없고 읽기만 허용되는 유일한 작업입니다.
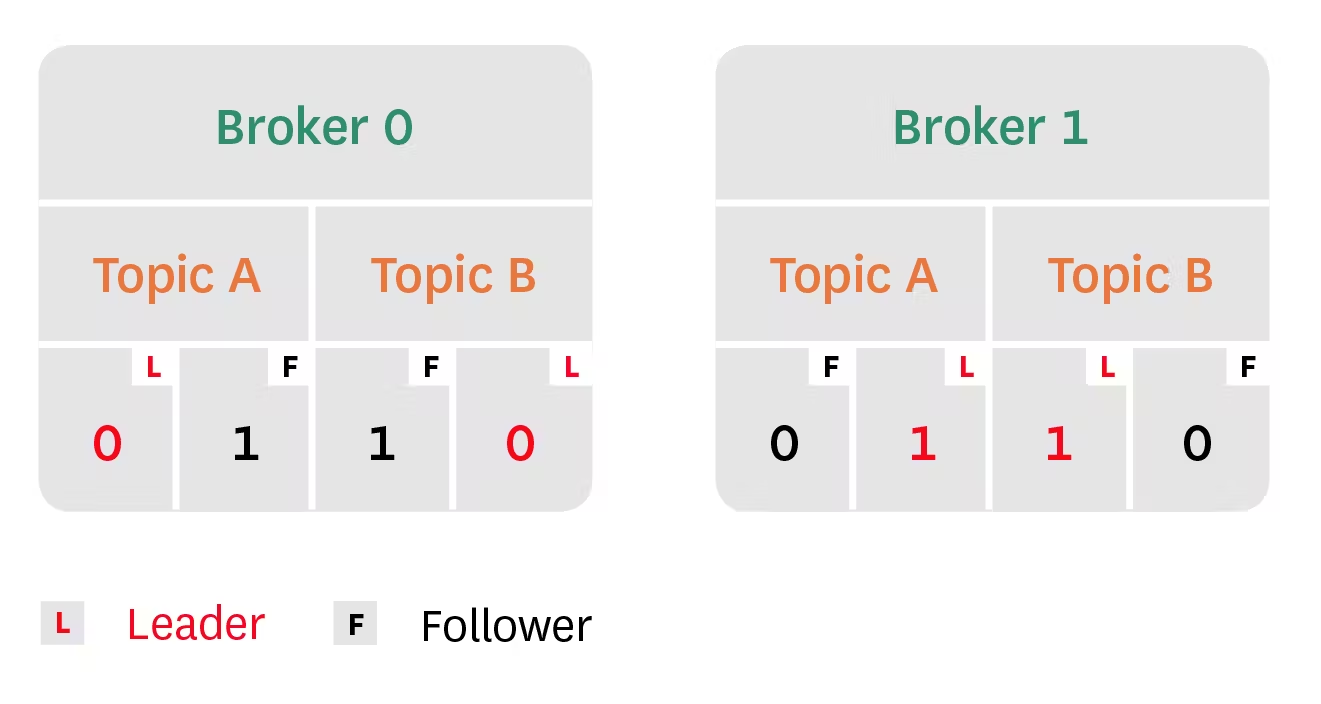
카프카는 메시지를 토픽으로 구성하여 관련 메시지를 저장하고, 소비자는 필요한 토픽을 구독합니다. 토픽은 그 자체로 파티션으로 나뉘며, 파티션은 브로커에 할당됩니다. 따라서 토픽은 브로커 수준에서 데이터의 샤딩을 시행합니다. 파티션 수가 많을수록 토픽이 지원할 수 있는 동시 소비자 수가 늘어납니다.
Kafka를 처음 설정할 때는 토픽당 충분한 수의 파티션을 할당하고 브로커 간에 파티션을 공정하게 분배하는 데 주의를 기울여야 합니다. Kafka를 처음 배포할 때 이렇게 하면 향후 성장통을 최소화할 수 있습니다. 적절한 토픽 및 파티션 수를 선택하는 방법에 대한 자세한 내용은 Confluent의 Jun Rao가 작성한 이 훌륭한 글을 참조하세요.
Kafka의 복제 기능은 선택적으로 여러 브로커에서 각 파티션을 유지함으로써 고가용성을 제공합니다. 복제된 파티션에서 Kafka는 하나의 복제본, 즉 파티션 리더에게만 메시지를 씁니다. 다른 복제본은 팔로워로, 리더로부터 메시지의 복사본을 가져옵니다. 소비자는 Kafka 버전 2.4부터 파티션 리더 또는 팔로워 중 하나에서 읽을 수 있습니다. (이전 버전에서는 소비자는 파티션 리더에서만 읽을 수 있었습니다.) 이 아키텍처는 여러 복제본에 걸쳐 요청 부하를 분산시킵니다.
또한 현재 리더가 오프라인 상태가 되면 팔로워가 동기화 복제본(ISR)으로 인식되는 경우 팔로워가 파티션 리더 역할을 할 수 있습니다. 팔로워가 파티션 리더에게 전송된 각 메시지를 성공적으로 가져와서 승인하면 팔로워가 동기화 중인 것으로 간주합니다. 리더가 오프라인 상태가 되면 Kafka는 ISR 세트에서 새 리더를 선출합니다. 그러나 브로커가 클린하지 않은 리더 선출을 허용하도록 구성된 경우(즉, unclean.leader.election.enable 값이 true인 경우) 동기화되지 않은 리더를 선출할 수 있습니다.
마지막으로, ZooKeeper 없이는 Kafka 배포가 완료되지 않습니다. ZooKeeper는 이 모든 것을 하나로 묶어주는 접착제이며, 그 역할을 담당합니다:
- 트롤러(파티션 리더를 관리하는 Kafka 브로커) 선출
- 클러스터 멤버십 기록
- 토픽 구성 유지 관리
- 생산자와 소비자의 처리량을 제한하기 위해 설정한 쿼터 적용
Kafka 모니터링을 위한 주요 메트릭
제대로 작동하는 Kafka 클러스터는 상당한 양의 데이터를 처리할 수 있습니다. 이에 의존하는 애플리케이션의 안정적인 성능을 유지하려면 Kafka 배포의 상태를 모니터링하는 것이 중요합니다.
Kafka 메트릭은 세 가지 범주로 나눌 수 있습니다:
- Kafka server (broker) metrics
- Producer metrics
- Consumer metrics
Kafka는 상태를 유지하기 위해 ZooKeeper에 의존하기 때문에 ZooKeeper를 모니터링하는 것도 중요합니다. Kafka 및 ZooKeeper 메트릭 수집에 대해 자세히 알아보려면 이 시리즈의 2부를 참조하세요.
이 문서에서는 메트릭 수집 및 알림을 위한 프레임워크를 제공하는 모니터링 101 시리즈에서 소개된 메트릭 용어를 참조합니다
Broker metrics
모든 메시지가 소비되려면 Kafka 브로커를 통과해야 하므로, 브로커 클러스터에서 발생하는 문제를 모니터링하고 경고하는 것이 매우 중요합니다. 브로커 메트릭은 세 가지 등급으로 분류할 수 있습니다:
- Kafka-emitted metrics
- Host-level metrics
- JVM garbage collection metrics
Kafka-emitted metrics
| Name | Mbean name | Description | Metric type |
|---|---|---|---|
| UnderReplicatedPartitions | kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions | 복제되지 않은 파티션 수 | Resource: Availability |
| IsrShrinksPerSec/IsrExpandsPerSec | kafka.server:type=ReplicaManager,name=IsrShrinksPerSec kafka.server:type=ReplicaManager,name=IsrExpandsPerSec |
동기화 복제본(ISR) 풀이 축소/확장되는 속도 | Resource: Availability |
| ActiveControllerCount | kafka.controller:type=KafkaController,name=ActiveControllerCount | 동클러스터의 active 컨트롤러 수 | Resource: Error |
| OfflinePartitionsCount | kafka.controller:type=KafkaController,name=OfflinePartitionsCount | 오프라인 파티션 수 | Resource: Availability |
| LeaderElectionRateAndTimeMs | kafka.controller:type=ControllerStats,name=LeaderElectionRateAndTimeMs | 리더 선출 비율 및 지연 시간 | Other |
| UncleanLeaderElectionsPerSec | kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec | 초당 'unclean' 선거 횟수 | Resource: Error |
| TotalTimeMs | kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower} | 지정된 요청을 처리하는 데 걸린 총 시간(ms)(Produce/Fetch) | Work: Performance |
| PurgatorySize | kafka.server:type=DelayedOperationPurgatory,name=PurgatorySize,delayedOperation={Produce|Fetch} | 지정된 요청을 처리하는 데 걸린 총 시간(ms)(Produce/Fetch) | Other |
| BytesInPerSec/BytesOutPerSec | kafka.server:type=BrokerTopicMetrics,name={BytesInPerSec|BytesOutPerSec} | 생산자 퍼지토리에서 대기 중인 요청 수/ 가져오기 퍼지토리에서 대기 중인 요청 수 | Work: Throughput |
| RequestsPerSecond | kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower},version={0|1|2|3|…} Number of (producer|consumer|follower) requests per second Work: Throughput | 총 바이트 수신/발신 속도 집계 | Work: Throughput |
UnderReplicatedPartitions
정상 클러스터에서는 동기화 중 복제본(ISR)의 수가 총 복제본 수와 정확히 같아야 합니다. 파티션 복제본이 리더 파티션보다 너무 뒤처지면 팔로워 파티션이 ISR 풀에서 제거되고 그에 따라 IsrShrinksPerSec이 증가합니다. 브로커를 사용할 수 없게 되면 UnderReplicatedPartitions의 값이 급격하게 증가합니다. 복제 없이는 Kafka의 고가용성 보장을 충족할 수 없으므로 이 메트릭 값이 오랜 기간 동안 0을 초과하는 경우 반드시 조사가 필요합니다.
IsrShrinksPerSec/IsrExpandsPerSec
브로커 클러스터를 확장하거나 파티션을 제거하는 경우를 제외하고 특정 파티션에 대한 동기화 복제본(ISR)의 수는 상당히 고정적으로 유지되어야 합니다. 고가용성을 유지하기 위해, 건강한 Kafka 클러스터에는 장애 조치를 위한 최소한의 ISR이 필요합니다. 복제본이 일정 시간 동안 리더에 연결되지 않으면 ISR 풀에서 제거될 수 있습니다(replica.socket.timeout.ms 매개변수로 구성 가능). 이러한 메트릭 값의 플랩핑이 있는지, 그리고 그 직후에 IsrExpandsPerSec의 증가 없이 IsrShrinksPerSec의 증가가 있는지 조사해야 합니다.
ActiveControllerCount
Kafka 클러스터에서 가장 먼저 부팅되는 노드는 자동으로 컨트롤러가 되며, 컨트롤러는 하나만 있을 수 있습니다. Kafka 클러스터의 컨트롤러는 파티션 리더 목록을 유지하고, 파티션 리더를 사용할 수 없게 되는 경우 리더십 전환을 조정하는 역할을 담당합니다. 컨트롤러를 교체해야 하는 경우, ZooKeeper는 브로커 풀에서 무작위로 새 컨트롤러를 선택합니다. 모든 브로커의 ActiveControllerCount 합은 항상 1이어야 하며, 1초 이상 지속되는 다른 값에 대해 알림을 보내야 합니다
OfflinePartitionsCount (controller only)
이 메트릭은 활성 리더가 없는 파티션의 수를 보고합니다. 모든 읽기 및 쓰기 작업은 파티션 리더에서만 수행되므로 이 메트릭의 값이 0이 아닌 경우 서비스 중단을 방지하기 위해 경고를 보내야 합니다. 활성 리더가 없는 파티션은 완전히 액세스할 수 없으며, 해당 파티션의 소비자와 생산자 모두 리더를 사용할 수 있게 될 때까지 차단됩니다.
LeaderElectionRateAndTimeMs
파티 리더가 사망하면 새 리더를 선출하기 위한 선거가 시작됩니다. 파티션 리더가 ZooKeeper에서 세션을 유지하지 못하면 “죽은” 것으로 간주됩니다. ZooKeeper의 Zab과 달리, 카프카는 리더 선출에 다수결 합의 알고리즘을 사용하지 않습니다. 대신, Kafka의 쿼럼은 특정 파티션에 대한 모든 동기화 복제본(ISR)의 집합으로 구성됩니다. 복제본이 리더를 따라잡으면 동기화 중인 것으로 간주되며, 이는 ISR의 모든 복제본이 리더로 승격될 수 있음을 의미합니다.
LeaderElectionRateAndTimeMs
리더 선출 비율(초당)과 클러스터에 리더가 없는 총 시간(밀리초 단위)을 보고합니다. UncleanLeaderElectionsPerSec만큼 나쁘지는 않지만, 이 메트릭을 계속 주시하고 싶을 것입니다. 위에서 언급했듯이 리더 선거는 현재 리더와의 연락이 끊어질 때 트리거되며, 이는 오프라인 브로커로 해석될 수 있습니다.
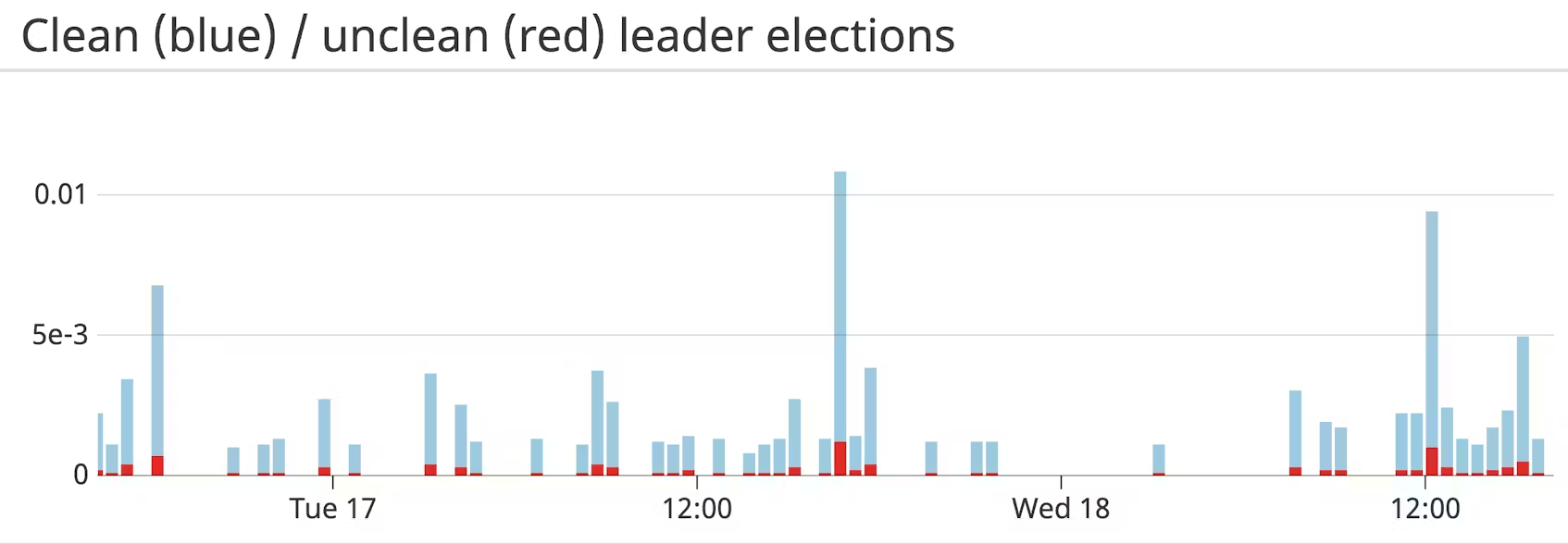
UncleanLeaderElectionsPerSec
부정 리더 선출은 카프카 브로커 중 자격을 갖춘 파티션 리더가 없을 때 발생합니다. 일반적으로 파티션의 리더인 브로커가 오프라인 상태가 되면 파티션의 ISR 집합에서 새 리더가 선출됩니다. Kafka 버전 0.11 이상에서는 기본적으로 리더 선출이 비활성화되어 있으므로, 새 리더로 선출할 ISR이 없는 경우 파티션이 오프라인 상태가 됩니다. 카프카가 unclean 리더 선출을 허용하도록 구성된 경우, 동기화되지 않은 복제본 중에서 리더가 선택되며, 이전 리더가 손실되기 전에 동기화되지 않은 모든 메시지는 영원히 손실됩니다. 기본적으로 부정 리더 선거는 가용성을 위해 일관성을 희생합니다. 이 메트릭은 데이터 손실을 의미하므로 주의해야 합니다.
TotalTimeMs TotalTimeMs 메트릭군은 요청을 서비스하는 데 걸린 총 시간을 측정합니다
(생산, 가져오기-소비자, 가져오기-팔로워 요청 등):
- produce: 생산자가 데이터를 전송하는 요청
- fetch-consumer: 새 데이터를 가져오기 위한 소비자의 요청
- fetch-follower: 파티션의 팔로워인 브로커가 새 데이터를 가져오기 위한 요청
총 시간 측정값 자체는 네 가지 메트릭의 합입니다:
- queue: 요청 큐에서 대기하는 데 소요된 시간
- 로컬: 리더가 처리하는 데 소요된 시간
- 원격: 팔로워 응답을 기다리는 데 소요된 시간(requests.required.acks=-1인 경우에만 해당)
- 응답: 응답을 보내는 데 걸린 시간
정상적인 조건에서 이 값은 최소한의 변동으로 상당히 정적이어야 합니다. 비정상적인 동작이 발생하는 경우 개별 대기열, 로컬, 원격 및 응답 값을 확인하여 속도 저하의 원인이 되는 정확한 요청 세그먼트를 찾아낼 수 있습니다.

PurgatorySize
요청 보관소는 처리되기를 기다리는 생산 및 가져오기 요청을 위한 임시 보관소 역할을 합니다. 각 요청 유형에는 요청이 퍼지오에 추가될지 여부를 결정하는 고유한 매개변수가 있습니다:
- fetch: fetch.wait.max.ms에 지정된 시간에 도달하거나 충분한 데이터를 사용할 수 있게 될 때까지 요청을 처리할 데이터가 충분하지 않으면(소비자의 경우 fetch.min.bytes) Fetch 요청이 퍼지토리에 추가됩니다.
- produce: request.required.acks=-1이면 파티션 리더가 모든 팔로워로부터 승인을 받을 때까지 모든 생성 요청이 퍼지토리로 이동합니다.
purgatory의 크기를 주시하는 것은 지연 시간의 근본적인 원인을 파악하는 데 유용합니다. 예를 들어 소비자 가져오기 시간의 증가는 퍼지토리에서 가져오기 요청의 수가 그에 상응하는 만큼 증가하면 쉽게 설명할 수 있습니다.
BytesInPerSec/BytesOutPerSec
일반적으로 디스크 처리량은 카프카 성능의 주요 병목 현상인 경향이 있습니다. 하지만 그렇다고 해서 네트워크가 병목 현상이 전혀 없다는 것은 아닙니다. 여러 데이터 센터에 걸쳐 메시지를 전송하는 경우, 토픽에 많은 수의 소비자가 있는 경우, 또는 복제본이 리더를 따라잡고 있는 경우 네트워크 처리량이 Kafka의 성능에 영향을 미칠 수 있습니다. 브로커의 네트워크 처리량을 추적하면 잠재적인 병목 현상이 발생할 수 있는 위치에 대한 자세한 정보를 얻을 수 있으며, 메시지의 종단 간 압축을 활성화할지 여부와 같은 결정을 내릴 수 있습니다.
RequestsPerSec
생산자, 소비자, 팔로워의 요청 비율을 모니터링하여 Kafka 배포가 효율적으로 통신하고 있는지 확인해야 합니다. 생산자가 더 많은 트래픽을 보내거나 배포가 확장되어 메시지를 가져와야 하는 소비자 또는 팔로워가 추가되면 Kafka의 요청 속도가 증가할 것으로 예상할 수 있습니다. 그러나 초당 요청 수가 여전히 높다면 생산자, 소비자 및/또는 브로커의 배치 크기를 늘리는 것을 고려해야 합니다. 이렇게 하면 요청 수를 줄여 불필요한 네트워크 오버헤드를 줄임으로써 Kafka 배포의 처리량을 개선할 수 있습니다.
Host-level broker metrics
| Name | Description | Metric type |
|---|---|---|
| Page cache reads ratio | 페이지 캐시에서 읽은 것과 디스크에서 읽은 것의 비율 | Resource: Saturation |
| Disk usage | 현재 사용 중인 디스크 공간과 사용 가능한 공간 비교 | Resource: Utilization |
| CPU usage | CPU 사용량 | Resource: Utilization |
| Network bytes sent/received | k네트워크 트래픽 인/아웃 | Resource: Utilization |
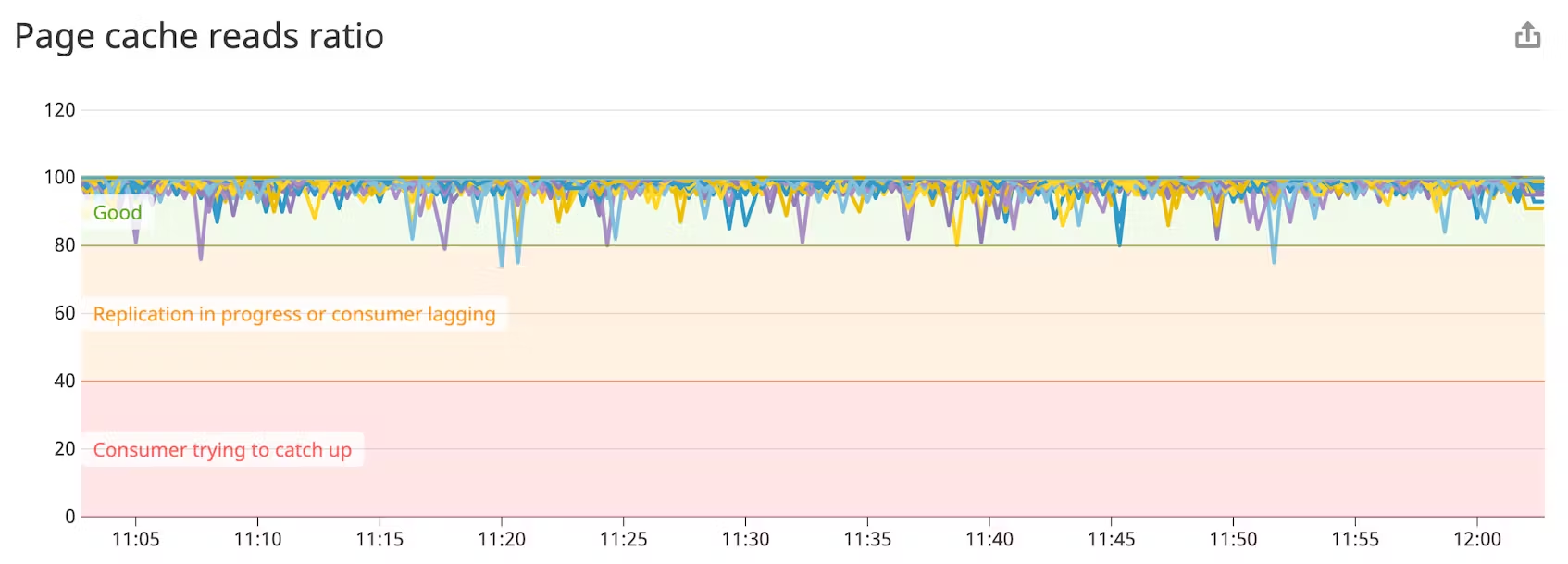
Page cache read ratio
Kafka는 처음부터 커널의 페이지 캐시를 활용하여 안정적이고(디스크 기반) 성능이 뛰어난(인메모리) 메시지 파이프라인을 제공하도록 설계되었습니다. 페이지 캐시 읽기 비율은 데이터베이스의 캐시 히트 비율과 유사하며, 값이 높을수록 읽기가 빨라지고 따라서 성능이 향상됩니다. 복제본이 리더를 따라잡는 경우(새 브로커가 생성될 때처럼) 이 메트릭은 잠시 떨어지지만 페이지 캐시 읽기 비율이 80% 미만으로 유지되면 추가 브로커를 프로비저닝하는 것이 도움이 될 수 있습니다.
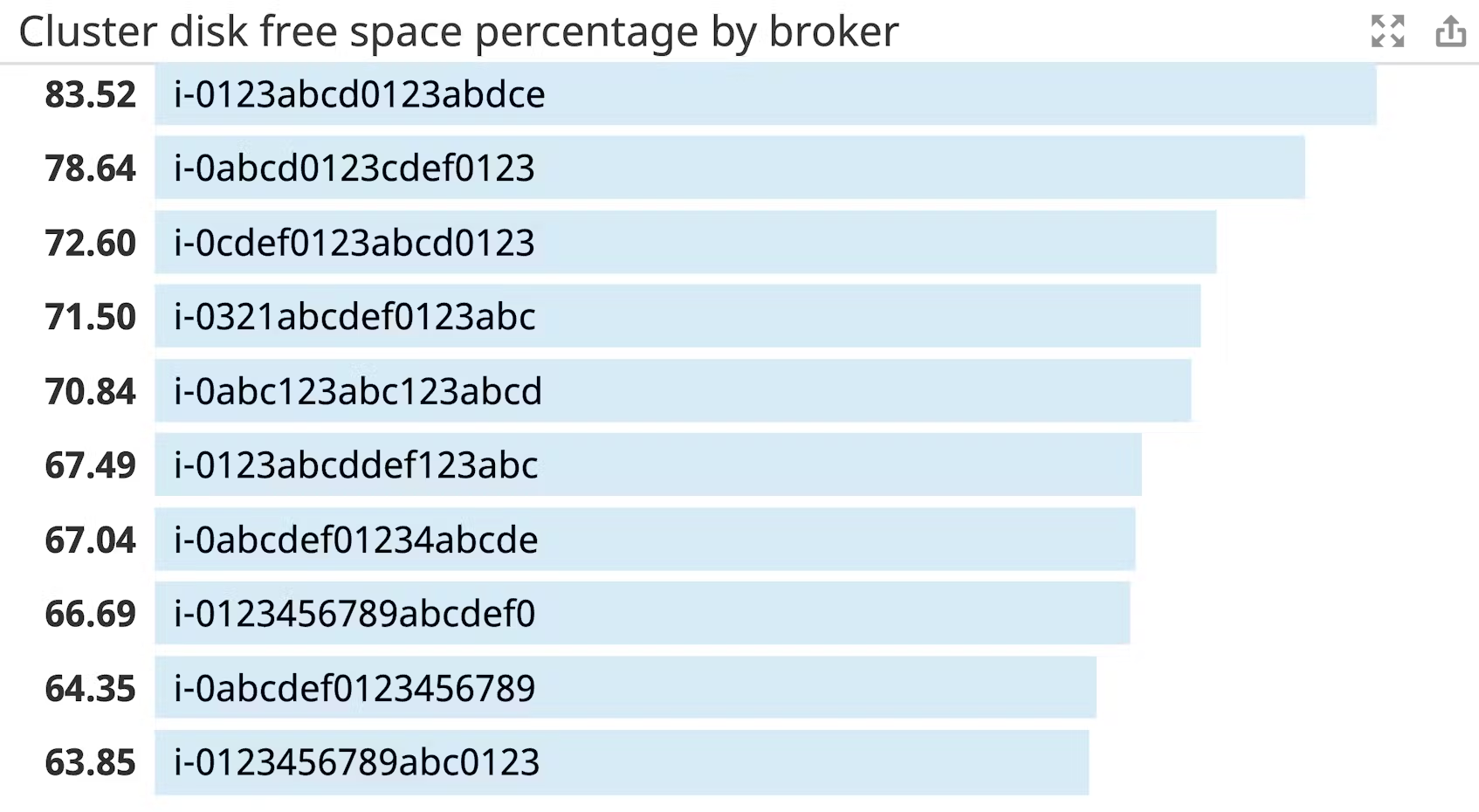
경고할 메트릭: 디스크 사용량 Kafka는 모든 데이터를 디스크에 보존하기 때문에 Kafka에서 사용할 수 있는 디스크 여유 공간을 모니터링해야 합니다. 디스크가 꽉 차면 Kafka가 실패하므로 시간 경과에 따른 디스크 증가를 추적하고 디스크 공간이 거의 다 사용되기 전에 적절한 시점에 관리자에게 알리도록 알림을 설정하는 것이 매우 중요합니다.
CPU 사용량
카프카의 주요 병목 현상은 일반적으로 메모리이지만, CPU 사용량을 주시하는 것도 나쁘지 않습니다. GZIP 압축이 활성화된 사용 사례에서도 CPU가 성능 문제의 원인이 되는 경우는 드뭅니다. 따라서 CPU 사용량이 급증하는 경우 이를 조사해 볼 필요가 있습니다.
네트워크 바이트 전송/수신
카프카의 바이트 입/출력 메트릭을 모니터링하는 경우, 카프카의 측면을 파악하고 있는 것입니다. 호스트의 네트워크 사용량을 전체적으로 파악하려면 호스트 수준의 네트워크 처리량을 모니터링해야 하며, 특히 Kafka 브로커가 다른 네트워크 서비스를 호스팅하는 경우 더욱 그렇습니다. 높은 네트워크 사용량은 성능 저하의 증상일 수 있으며, 높은 네트워크 사용량을 보이는 경우 TCP 재전송 및 패킷 오류 삭제와의 상관관계를 파악하면 성능 문제가 네트워크와 관련이 있는지 판단하는 데 도움이 될 수 있습니다.
JVM garbage collection metrics
Kafka는 Scala로 작성되고 Java 가상 머신(JVM)에서 실행되므로 메모리를 확보하기 위해 Java 가비지 수집 프로세스에 의존합니다. Kafka 클러스터의 활동이 많을수록 가비지 컬렉션이 더 자주 실행됩니다.
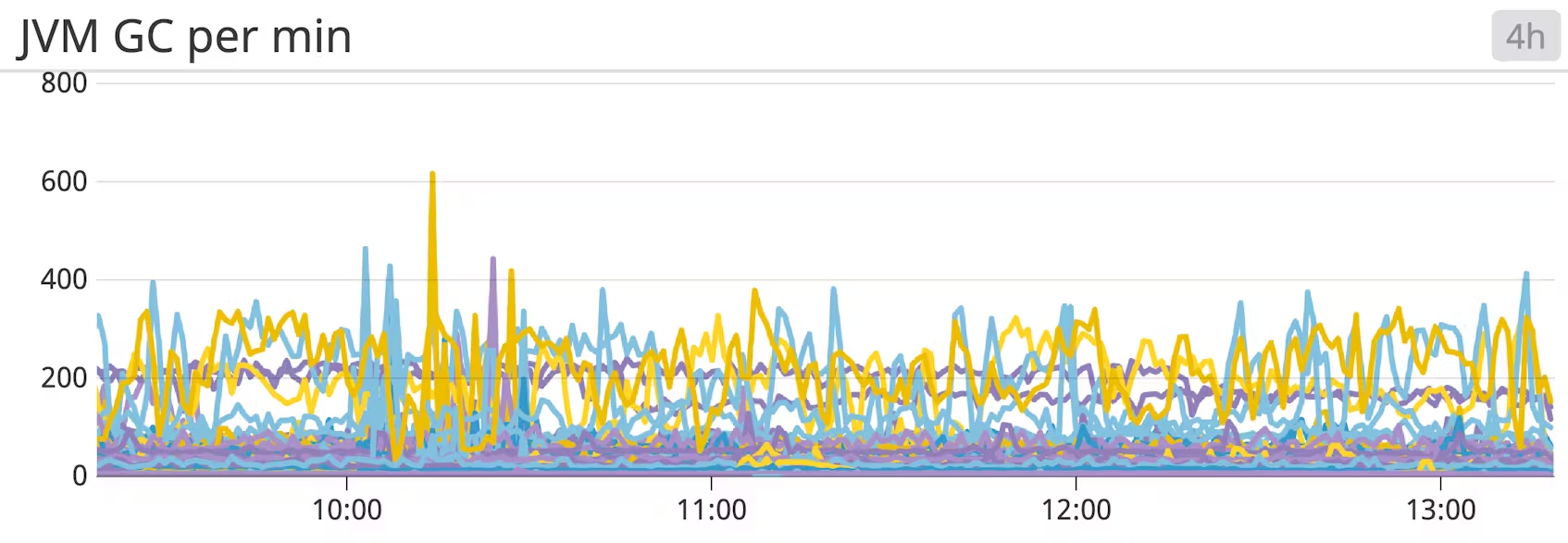
Java 애플리케이션에 익숙한 사람이라면 가비지 컬렉션이 높은 성능 비용을 초래할 수 있다는 것을 알고 있습니다. 가비지 컬렉션으로 인한 긴 일시 정지의 가장 눈에 띄는 효과는 (세션 시간 초과로 인해) 중단된 ZooKeeper 세션의 증가입니다.
가비지 컬렉션의 유형은 젊은 세대(새 개체) 또는 오래된 세대(오래 살아남은 개체)가 수집되는지에 따라 달라집니다. Java 가비지 컬렉션에 대한 좋은 입문서는 이 [페이지를 참조] (https://engineering.linkedin.com/garbage-collection/garbage-collection-optimization-high-throughput-and-low-latency-java-applications)하세요.
가비지 수집 중에 과도하게 일시 중지되는 경우 JDK 버전 또는 가비지 수집기를 업그레이드하거나 zookeeper.session.timeout.ms의 시간 초과 값을 확장하는 것이 좋습니다. 또한 가비지 수집을 최소화하도록 Java 런타임을 조정할 수도 있습니다. LinkedIn의 엔지니어가 JVM 가비지 수집 최적화에 대해 자세히 설명하는 글을 작성했습니다. 물론 Kafka 문서에서 몇 가지 권장 사항을 확인할 수도 있습니다.
| Name | Mbean name | Description | Metric type |
|---|---|---|---|
| CollectionCount | java.lang:type=GarbageCollector,name=G1 (Young|Old) Generation | JVM이 실행한 젊은 또는 오래된 가비지 수집 프로세스의 총 개수입니다 | Other |
| CollectionTime | java.lang:type=GarbageCollector,name=G1 (Young|Old) Generation | JVM이 최근 또는 오래된 가비지 수집 프로세스를 실행하는 데 소요된 총 시간(밀리초) | Other |
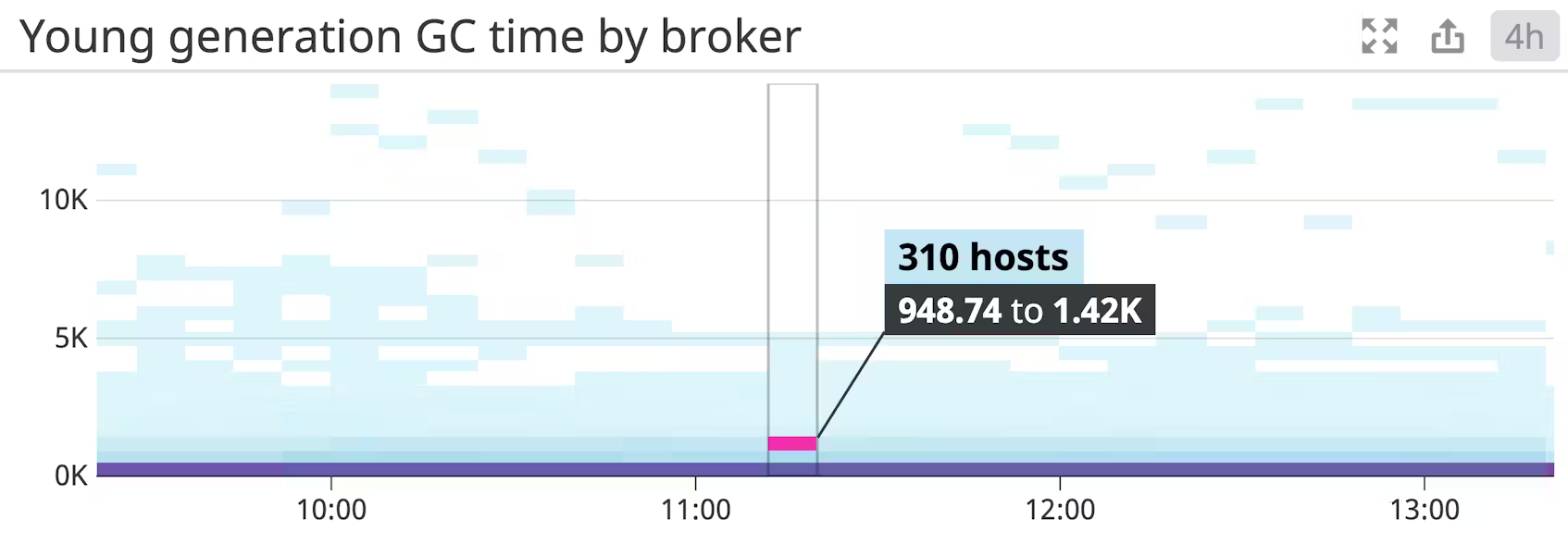
Young generation garbage collection time
젊은 세대 가비지 컬렉션은 비교적 자주 발생합니다. 이는 가비지 수집이 수행되는 동안 모든 애플리케이션 스레드가 일시 중지되는 중지 가비지 수집입니다. 이 메트릭의 값이 크게 증가하면 Kafka의 성능에 큰 영향을 미칩니다.
Old generation garbage collection count/time
오래전에 생성한 가비지 컬렉션은 이전 세대의 힙에서 사용하지 않는 메모리를 확보합니다. 이는 일시 중지 가비지 수집으로, 애플리케이션 스레드를 일시적으로 중단하지만 간헐적으로만 중단합니다. 이 프로세스가 완료되는 데 몇 초가 걸리거나 빈도가 증가하면 클러스터가 효율적으로 작동하기에 메모리가 충분하지 않을 수 있습니다.
Kafka producer metrics
카프카 프로듀서는 소비를 위해 토픽을 중개하기 위해 메시지를 푸시하는 독립적인 프로세스입니다. 프로듀서가 실패하면 소비자는 새로운 메시지를 받지 못하게 됩니다. 다음은 들어오는 데이터의 안정적인 스트림을 보장하기 위해 모니터링해야 할 가장 유용한 프로듀서 메트릭 몇 가지입니다.
| Name | Mbean name | Description | Metric type |
|---|---|---|---|
| compression-rate-avg | kafka.producer:type=producer-metrics,client-id=([-.w]+) | 전송된 배치의 평균 압축률 | Work: Other |
| Colresponse-ratelectionTime | kafka.producer:type=producer-metrics,client-id=([-.w]+) | 초당 평균 수신 응답 수 | Work: Throughput |
| request-rate | kafka.producer:type=producer-metrics,client-id=([-.w]+) | 초당 평균 요청 전송 횟수 | Work: Throughput |
| request-latency-avg | jkafka.producer:type=producer-metrics,client-id=([-.w]+) | 평균 요청 지연 시간(ms) | Work: Throughput |
| outgoing-byte-rate | jkafka.producer:type=producer-metrics,client-id=([-.w]+) | 초당 평균 발신/수신 바이트 수 | Work: Throughput |
| io-wait-time-ns-avg | jkafka.producer:type=producer-metrics,client-id=([-.w]+) | I/O 스레드가 소켓을 대기하는 데 소요된 평균 시간(ns) | Work: Throughput |
| batch-size-avg | jkafka.producer:type=producer-metrics,client-id=([-.w]+) | 요청당 파티션당 전송된 평균 바이트 수 | Work: Throughput |
Compression rate
이 메트릭은 생산자가 브로커에 전송하는 데이터 배치의 데이터 압축량을 반영합니다. 압축률은 압축되지 않은 크기와 비교한 배치의 압축된 크기의 평균 비율입니다. 압축률이 작을수록 효율성이 높다는 뜻입니다. 이 지표가 상승하면 데이터 형태에 문제가 있거나 불량 생산자가 압축되지 않은 데이터를 전송하고 있음을 나타낼 수 있습니다.
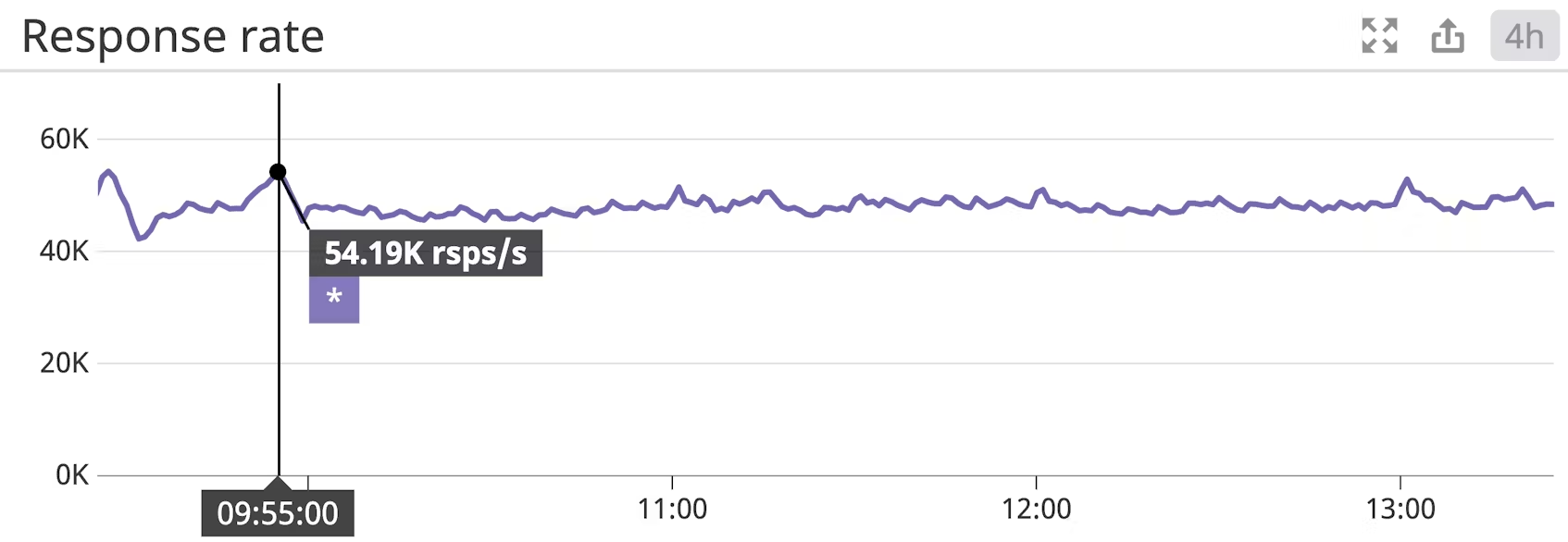
Response rate
프로듀서의 경우 응답률은 브로커로부터 받은 응답의 비율을 나타냅니다. 브로커는 데이터가 수신되면 프로듀서에게 응답합니다. 구성에 따라 “수신됨”은 세 가지 의미 중 하나를 가질 수 있습니다:
- 메시지가 수신되었지만 커밋되지 않음(request.required.acks == 0)
- 리더가 메시지를 디스크에 썼습니다(request.required.acks == 1)
- 리더가 모든 레플리카로부터 데이터가 디스크에 기록되었다는 확인을 받았습니다(request.required.acks == all)
필요한 수의 확인을 받을 때까지 프로듀서 데이터를 사용할 수 없습니다.
응답률이 낮다면 여러 가지 요인이 작용하고 있을 수 있습니다. 먼저 브로커의 request.required.acks 설정 지시문을 확인하는 것이 좋습니다. 요청.required.acks에 적합한 값을 선택하는 것은 전적으로 사용 사례에 따라 다르며, 가용성과 일관성을 맞바꾸고 싶은지 여부는 사용자가 결정할 수 있습니다.
Request rate
요청 비율은 프로듀서가 브로커에게 데이터를 전송하는 비율입니다. 물론 정상적인 요청 비율을 구성하는 요소는 사용 사례에 따라 크게 달라질 수 있습니다. 지속적인 서비스 가용성을 보장하기 위해서는 최고치와 최저치를 주시하는 것이 필수적입니다. 속도 제한을 사용하지 않으면 트래픽이 급증하는 경우 브로커가 급격한 데이터 유입을 처리하는 데 어려움을 겪으면서 속도가 느려질 수 있습니다.
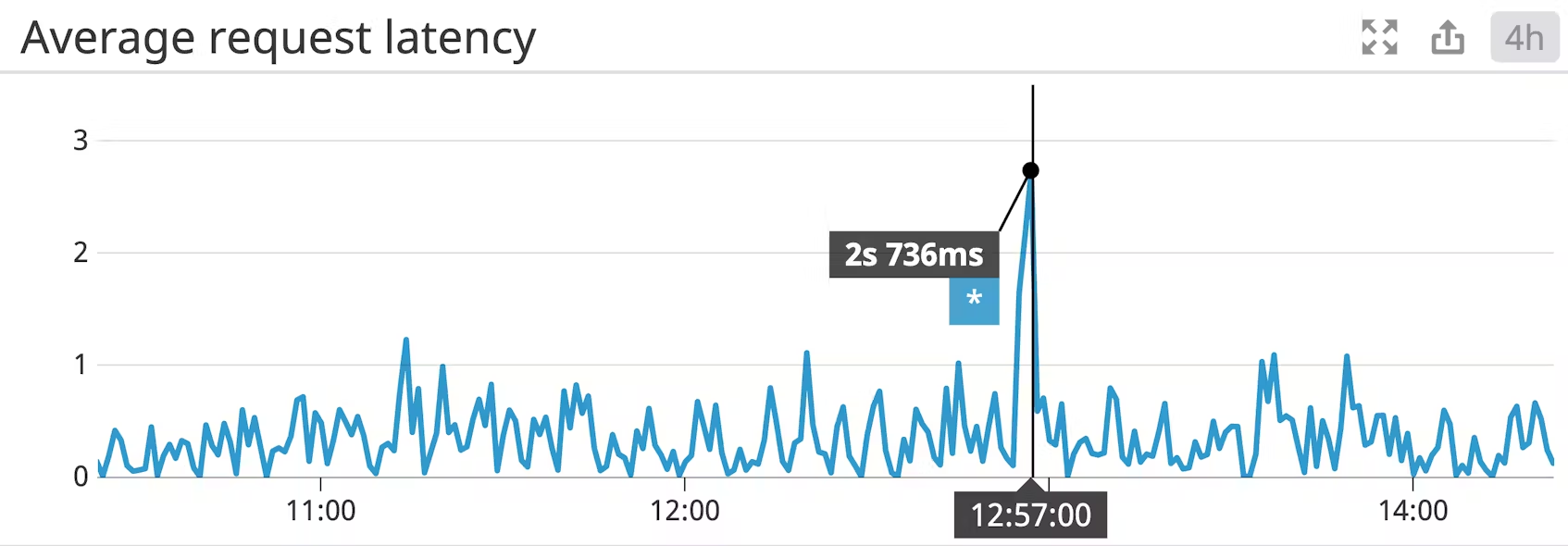
Request latency average
평균 요청 지연 시간은 KafkaProducer.send()가 호출된 시점부터 프로듀서가 브로커로부터 응답을 받을 때까지의 시간을 측정한 값입니다. 여기서 “수신”은 응답 속도에 대한 단락에서 설명한 것처럼 여러 가지를 의미할 수 있습니다.
프로듀서가 각 메시지를 생성하자마자 반드시 전송하는 것은 아닙니다. 프로듀서의 linger.ms 값은 메시지 배치를 보내기 전에 대기할 최대 시간을 결정하므로, 한 번의 요청으로 메시지를 보내기 전에 더 많은 메시지를 누적할 수 있습니다. linger.ms의 기본값은 0ms이며, 이 값을 높게 설정하면 지연 시간이 늘어날 수 있지만 제작자가 각 메시지에 대한 네트워크 오버헤드 없이 여러 메시지를 보낼 수 있으므로 처리량을 개선하는 데 도움이 될 수 있습니다. Kafka 배포의 처리량을 개선하기 위해 linger.ms를 늘리는 경우 요청 지연 시간을 모니터링하여 허용 가능한 한도를 초과하지 않는지 확인해야 합니다.
지연 시간은 처리량과 밀접한 상관관계가 있으므로 프로듀서 구성에서 batch.size를 수정하면 처리량이 크게 향상될 수 있습니다. 최적의 배치 크기를 결정하는 것은 사용 사례에 따라 크게 달라지지만 일반적으로 사용 가능한 메모리가 있으면 배치 크기를 늘려야 합니다. 구성하는 배치 크기는 상한선이라는 점에 유의하세요. 배치 크기가 작을수록 더 많은 네트워크 라운드 트립이 발생하므로 처리량이 감소할 수 있습니다.
Outgoing byte rate
카프카 브로커와 마찬가지로 프로듀서 네트워크 처리량을 모니터링하고 싶을 것입니다. 시간 경과에 따른 트래픽 양을 관찰하는 것은 네트워크 인프라를 변경할 필요가 있는지 여부를 결정하는 데 필수적입니다. 프로듀서 네트워크 트래픽을 모니터링하면 인프라 변경에 대한 결정을 내리는 데 도움이 될 뿐만 아니라 프로듀서의 생산 속도를 파악하고 과도한 트래픽의 원인을 파악하는 데도 도움이 됩니다.
I/O wait time
프로듀서는 일반적으로 데이터를 기다리거나 데이터를 전송하는 두 가지 중 하나를 수행합니다. 프로듀서가 전송할 수 있는 데이터보다 더 많은 데이터를 생성하는 경우 네트워크 리소스를 기다리게 됩니다. 하지만 프로듀서가 속도 제한을 받지 않거나 대역폭을 최대로 사용하지 않는다면 병목 현상을 파악하기가 더 어려워집니다. 디스크 액세스는 모든 처리 작업 중 가장 느린 경향이 있으므로 프로듀서의 I/O 대기 시간을 확인하는 것이 좋은 출발점입니다. I/O 대기 시간은 CPU가 유휴 상태인 동안 I/O를 수행하는 데 소요된 시간의 비율을 나타냅니다. 대기 시간이 과도하게 길다면 프로듀서가 필요한 데이터를 충분히 빠르게 얻을 수 없다는 뜻입니다. 스토리지 백엔드에 기존 하드 드라이브를 사용하는 경우 SSD를 고려할 수 있습니다.
batch.size
네트워크 리소스를 보다 효율적으로 사용하기 위해 Kafka 프로듀서는 메시지를 보내기 전에 메시지를 일괄 처리로 그룹화하려고 시도합니다. 프로듀서는 batch.size(기본값은 16KB)로 정의된 양의 데이터가 축적될 때까지 기다리지만, linger.ms(기본값은 0밀리초)보다 더 오래 기다리지는 않습니다.) 프로듀서가 전송하는 배치의 크기가 구성된 batch.size보다 지속적으로 작으면, 프로듀서가 도착하지 않는 추가 데이터를 기다리느라 대기 시간이 낭비됩니다. 배치 크기 값이 구성된 batch.size보다 작으면 linger.ms 설정을 줄이는 것이 좋습니다.
Kafka consumer metrics
| JMX attribute | Mbean name | Description | Metric type |
|---|---|---|---|
| records-lag | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+),topic=([-.w]+),partition=([-.w]+) | 이 파티션에서 (생산자 offset - 소비자 offset) 차의 offset 메시지 수 | Work: Performance |
| records-lag-max | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+),topic=([-.w]+),partition=([-.w]+) | 특정 파티션 또는 이 클라이언트의 모든 파티션에 대해 (생산자 offset - 소비자 offset)의 최대 메시지 수 | Work: Performance |
| bytes-consumed-rate | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+),topic=([-.w]+),partition=([-.w]+) | 특정 토픽 또는 모든 토픽에 대해 초당 소비되는 평균 바이트 수 | Work: Throughput |
| records-consumed-rate | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+),topic=([-.w]+),partition=([-.w]+) | 특정 토픽 또는 모든 토픽에 대해 초당 소비되는 평균 레코드 수 | Work: Performance |
| fetch-rate | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+),topic=([-.w]+),partition=([-.w]+) | 소비자의 초당 가져오기 요청 횟수 | Work: Throughput |
Records lag/Records lag max
레코드 지연은 소비자의 현재 로그 오프셋과 생산자의 현재 로그 오프셋 간의 계산된 차이입니다. 레코드 지연 최대값은 레코드 지연의 최대 관측값입니다. 이러한 메트릭 값의 중요성은 전적으로 소비자의 행동에 따라 달라집니다. 오래된 메시지를 장기 저장소에 백업하는 소비자가 있다면 레코드 지연이 상당히 클 것으로 예상할 수 있습니다. 그러나 소비자가 실시간 데이터를 처리하는 경우 지속적으로 높은 지연 값은 과부하가 걸린 소비자의 신호일 수 있으며, 이 경우 더 많은 소비자를 프로비저닝하고 토픽을 더 많은 파티션으로 분할하면 처리량을 늘리고 지연을 줄이는 데 도움이 될 수 있습니다
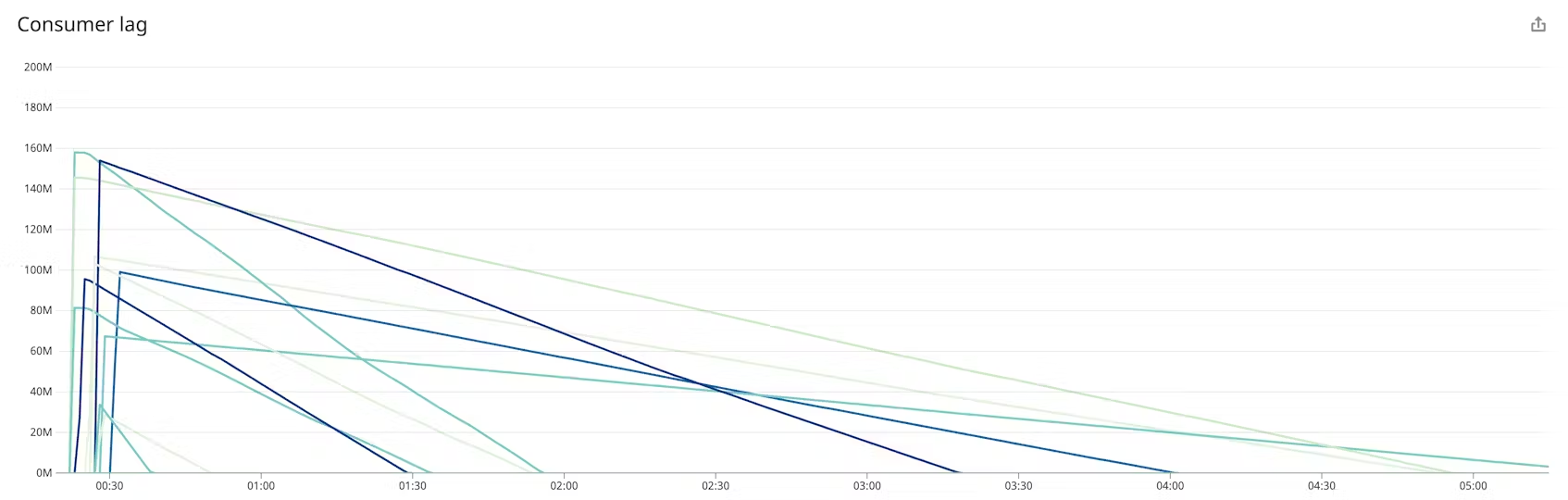
records consumed rate
각 Kafka 메시지는 하나의 데이터 레코드입니다. 메시지의 크기가 다양할 수 있기 때문에 초당 소비되는 레코드 수는 소비되는 바이트 수와 큰 상관관계가 없을 수 있습니다. 생산자와 워크로드에 따라 다르지만, 일반적인 배포에서는 이 수치가 상당히 일정하게 유지될 것으로 예상해야 합니다. 이 메트릭을 시간 경과에 따라 모니터링하면 데이터 소비의 추세를 발견하고 경고를 보낼 수 있는 기준선을 만들 수 있습니다.
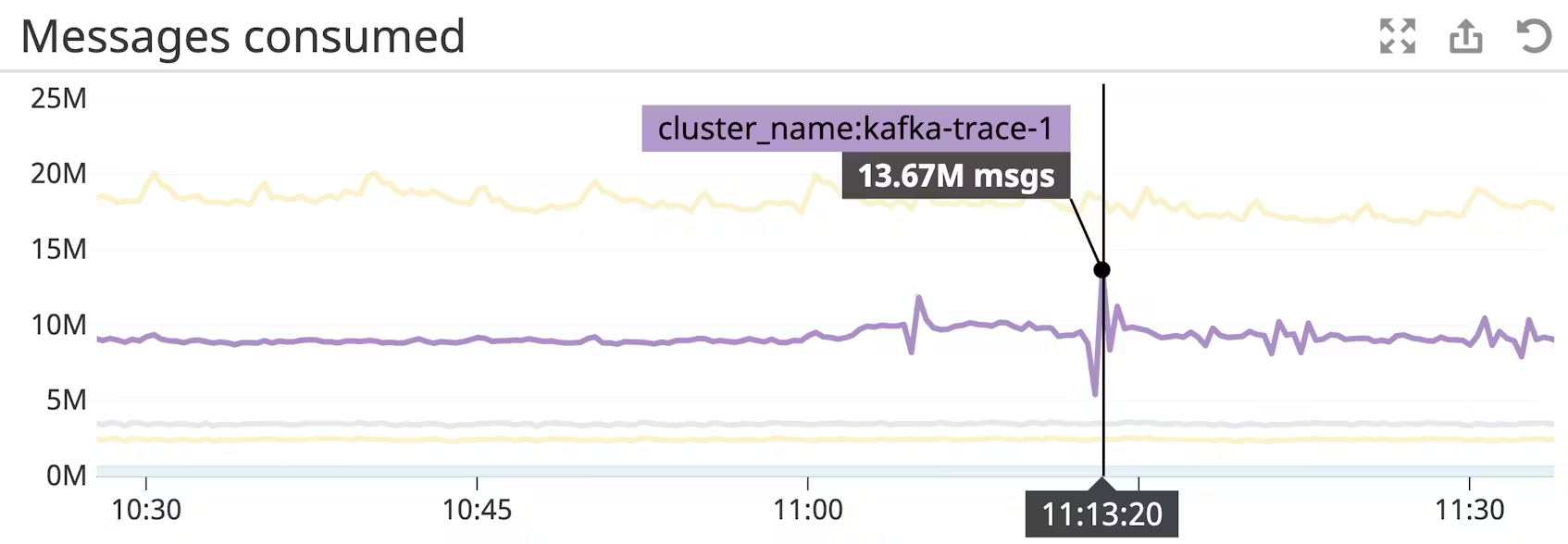
fetch rate
소비자의 가져오기 비율은 전반적인 소비자 상태를 나타내는 좋은 지표가 될 수 있습니다. 최소 가져오기 비율이 0에 가까워지면 잠재적으로 소비자에 문제가 있다는 신호일 수 있습니다. 건강한 소비자의 경우 최소 가져오기 비율은 일반적으로 0이 아니므로 이 값이 떨어지면 소비자 실패의 신호일 수 있습니다.
Why ZooKeeper?
ZooKeeper는 Kafka 배포에서 중요한 역할을 합니다. Kafka의 브로커와 토픽에 대한 정보를 유지하고, 배포를 통해 이동하는 트래픽 속도를 관리하기 위해 할당량을 적용하며, 배포 상태가 변경될 때 Kafka가 파티션 리더를 선출할 수 있도록 복제본에 대한 정보를 저장하는 일을 담당합니다. ZooKeeper는 Kafka 배포의 중요한 구성 요소이며, ZooKeeper가 중단되면 Kafka가 중단됩니다. 안정적인 Kafka 클러스터를 실행하려면 ZooKeeper를 앙상블이라는 고가용성 구성으로 배포해야 합니다. 그러나 앙상블을 실행하든 단일 ZooKeeper 호스트를 실행하든, ZooKeeper를 모니터링하는 것은 건강한 Kafka 클러스터를 유지하는 데 있어 핵심입니다.
ZooKeeper는 MBeans를 통해, 4글자 단어를 사용하는 명령줄 인터페이스를 통해, 그리고 관리자 서버에서 제공하는 HTTP 엔드포인트로 메트릭을 노출합니다. ZooKeeper 메트릭 수집에 대한 자세한 내용은 이 시리즈의 2부를 확인하세요.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| outstanding_requests | 대기 중인 요청 수 | Resource: Saturation | Four-letter words, AdminServer, JMX |
| avg_latency | 클라이언트 요청에 응답하는 데 걸리는 시간 | Work: Throughput | Four-letter words, AdminServer, JMX |
| num_alive_connections | ZooKeeper에 연결된 클라이언트 수 | Resource: Availability | Four-letter words, AdminServer, JMX |
| followers | active 팔로워 수 | Resource: Availability | Four-letter words, AdminServer |
| pending_syncs | 팔로워의 보류 중인 동기화 건수 | Other | Four-letter words, AdminServer, JMX |
| open_file_descriptor_count | 사용 중인 파일 descriptors 수 | Resource: Utilization | FFour-letter words, AdminServer |
Outstanding requests
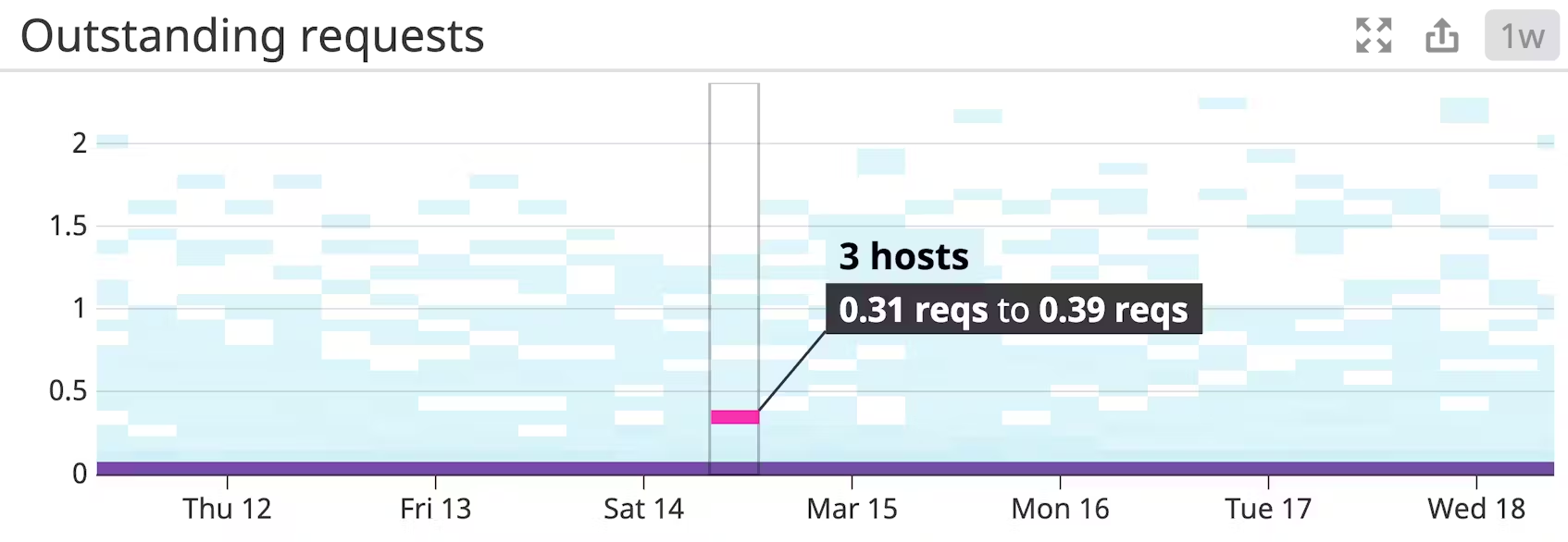
클라이언트가 요청을 처리할 수 있는 속도보다 더 빨리 요청을 제출할 수 있습니다. 클라이언트가 많은 경우, 이런 일이 가끔 발생하는 것은 거의 당연한 일입니다. 대기 중인 요청으로 인해 사용 가능한 메모리가 모두 소모되는 것을 방지하기 위해, ZooKeeper는 대기열 제한에 도달하면 클라이언트를 스로틀링합니다. 이 제한은 ZooKeeper의 zookeeper.globalOutstandingLimit 설정에 정의되어 있으며, 기본값은 1,000으로 설정되어 있습니다. 요청이 처리될 때까지 일정 시간 동안 대기하는 경우 보고된 평균 지연 시간에서 상관관계를 확인할 수 있습니다. 미처리 요청과 지연 시간을 모두 추적하면 성능 저하의 원인을 보다 명확하게 파악할 수 있습니다.
Average latency
평균 요청 지연 시간은 ZooKeeper가 요청에 응답하는 데 걸리는 평균 시간(밀리초)입니다. ZooKeeper는 트랜잭션을 트랜잭션 로그에 기록할 때까지 요청에 응답하지 않습니다. ZooKeeper 앙상블의 성능이 저하되는 경우, 평균 지연 시간을 미처리 요청 및 보류 중인 동기화(아래에서 자세히 설명)와 연관시켜 속도 저하의 원인에 대한 통찰력을 얻을 수 있습니다.
Number of alive connections
ZooKeeper는 num_alive_connections 메트릭을 통해 연결된 클라이언트 수를 보고합니다. 이는 ZooKeeper가 아닌 노드에 대한 연결을 포함한 모든 연결을 나타냅니다. 대부분의 환경에서 이 숫자는 상당히 정적으로 유지되어야 하며, 일반적으로 소비자, 프로듀서, 브로커, ZooKeeper 노드의 수는 비교적 안정적으로 유지되어야 합니다. 이 값의 예상치 못한 하락에 주의해야 합니다. Kafka는 ZooKeeper를 사용하여 작업을 조정하기 때문에, 연결이 끊어진 클라이언트에 따라 ZooKeeper에 대한 연결이 끊어지면 여러 가지 다른 영향을 미칠 수 있습니다.
Followers (leader only)
팔로워 수는 ZooKeeper 앙상블의 총 크기에서 1을 뺀 수와 같아야 합니다. (리더는 팔로워 수에 포함되지 않습니다). 앙상블의 크기는 사용자 개입(예: 관리자가 노드를 해제하거나 위임한 경우)으로 인해 변경되어야 하므로 이 값에 변경이 있을 경우 알림을 보내야 합니다.
Pending syncs (leader only) 트랜잭션 로그는 ZooKeeper에서 가장 성능이 중요한 부분입니다. ZooKeeper는 응답을 반환하기 전에 트랜잭션을 디스크에 동기화해야 하므로 보류 중인 동기화가 많으면 대기 시간이 늘어납니다. 미결 동기화 기간이 길어지면 의심할 여지 없이 성능이 저하되는데, 이는 동기화가 수행될 때까지 ZooKeeper가 요청을 서비스할 수 없기 때문입니다. pending_syncs 값이 10보다 크면 알림을 고려해야 합니다.
Open file descriptor count
ZooKeeper는 파일 시스템의 상태를 유지 관리하며, 각 z노드는 디스크의 하위 디렉터리에 해당합니다. Linux에서는 사용할 수 있는 파일 descriptor의 수가 제한되어 있습니다. 이는 구성할 수 있으므로 이 메트릭을 시스템의 구성된 제한과 비교하여 필요에 따라 제한을 늘려야 합니다.
ZooKeeper system metrics
ZooKeeper 자체에서 생성하는 메트릭 외에도 몇 가지 호스트 수준의 ZooKeeper 메트릭도 모니터링할 가치가 있습니다.
| Name | Description | Metric type | |
|---|---|---|---|
| Bytes sent/received | ZooKeeper 호스트가 송수신한 바이트 수 | Resource: Utilization | |
| Usable memory | ZooKeeper에서 사용 가능한 미사용 메모리 양 | Resource: Utilization | |
| Swap usage | ZooKeeper가 사용하는 스왑 공간의 양 | Resource: Saturation | |
| Disk latency | 데이터 요청과 디스크에서 데이터 반환 사이의 시간 지연 | Resource: Saturation | Four-letter words, AdminServer |
Bytes sent/received
많은 소비자와 파티션이 있는 대규모 배포에서 ZooKeeper는 클러스터의 변화하는 상태를 기록하고 전달하기 때문에 병목 현상이 발생할 수 있습니다. 시간 경과에 따른 송수신 바이트 수를 추적하면 성능 문제를 진단하는 데 도움이 될 수 있습니다. ZooKeeper 앙상블의 트래픽이 증가하는 경우, 더 많은 노드를 프로비저닝하여 더 많은 볼륨을 수용해야 합니다.
Usable memory
ZooKeeper는 전적으로 RAM에 상주해야 하며, 디스크로 페이지해야 하는 경우 상당한 성능 저하를 겪게 됩니다. 따라서 사용 가능한 메모리 양을 추적하여 ZooKeeper의 성능을 최적으로 유지해야 합니다. ZooKeeper는 상태를 저장하는 데 사용되므로, ZooKeeper 성능이 저하되면 클러스터 전체에 영향을 미친다는 점을 기억하세요. ZooKeeper 노드로 프로비저닝된 머신에는 부하 급증을 처리할 수 있는 충분한 메모리 버퍼가 있어야 합니다.
Swap usage
ZooKeeper의 메모리가 부족하면 스왑을 해야 하며, 이로 인해 속도가 느려질 수 있습니다. 더 많은 메모리를 프로비저닝할 수 있도록 스왑 사용량에 대한 알림을 받아야 합니다.
Disk latency
ZooKeeper는 RAM에 상주해야 하지만, 현재 상태를 주기적으로 스냅샷하고 모든 트랜잭션의 로그를 유지하기 위해 여전히 파일 시스템을 사용합니다. ZooKeeper는 업데이트가 수행되기 전에 비휘발성 스토리지에 트랜잭션을 기록해야 하므로 디스크 액세스가 잠재적인 병목 현상을 일으킬 수 있습니다. 디스크 지연 시간이 급증하면 ZooKeeper와 통신하는 모든 호스트의 서비스가 저하될 수 있으므로 앙상블에 SSD를 장착하는 것 외에도 디스크 지연 시간을 주시해야 합니다.
purgatory
-
purgatory란: Kafka에서 purgatory란 특정 요청이 조건을 만족할 때까지 보류되며, 대기 상태로 처리되는 구조를 의미합니다. Kafka에는 대표적으로 Producer Purgatory와 Fetch Purgatory라는 두 가지 종류의 purgatory가 존재합니다.
-
Producer Purgatory Producer Purgatory는 프로듀서(producer)로부터 메시지를 받았을 때 지정된 조건이 충족될 때까지 해당 요청을 대기시키는 Kafka 내부 구조입니다. 대표적인 경우로는 acks 설정이 있습니다. 프로듀서의 acks 값은 메시지가 정상적으로 브로커에 저장되었을 때 응답을 기다리는 정도를 설정하는 옵션으로, 0, 1, -1(all) 등으로 설정할 수 있습니다.
acks=1: 리더 복제본이 메시지를 받아들이면 즉시 응답을 반환합니다. acks=-1 (all): 모든 팔로워 복제본까지 메시지가 복제될 때까지 기다렸다가 응답합니다.
예를 들어, 프로듀서가 acks=-1로 설정했을 때 모든 팔로워가 복제 완료 상태가 되어야만 요청이 완료되므로, 모든 팔로워가 복제본을 수신할 때까지 요청이 Producer Purgatory에 머물게 됩니다. 이 때까지 해당 요청은 응답을 보류하는 상태가 되며, 특정 조건을 만족하는 순간 Purgatory에서 빠져나가게 됩니다.
Producer Purgatory의 주요 기능:
복제 일관성 유지: 요청이 모두 복제될 때까지 대기함으로써, 메시지 복제와 데이터 일관성을 보장합니다. 성능 최적화: Kafka는 이러한 대기 구조를 통해 비동기 처리를 최적화하여, 효율적인 데이터 전송과 복제를 수행할 수 있습니다.
- Fetch Purgatory Fetch Purgatory는 컨슈머(consumer)가 데이터를 요청할 때 특정 조건을 만족할 때까지 요청을 대기시키는 구조입니다. 컨슈머가 Kafka로부터 데이터를 읽을 때, 요청하는 데이터가 아직 준비되지 않았거나 특정 조건에 맞는 데이터가 없다면, 해당 요청이 Fetch Purgatory에 추가됩니다. 이 구조는 주로 데이터의 최소 레코드 수 또는 최소 바이트 수에 도달할 때까지 기다리도록 설정된 경우에 사용됩니다.
예를 들어, 컨슈머가 특정 오프셋부터 최소 5MB 이상의 데이터를 가져오기를 요청했을 때, 해당 데이터가 준비될 때까지 요청은 Fetch Purgatory에 머물며, 데이터를 충분히 수집한 후에 응답하게 됩니다.
Fetch Purgatory의 주요 기능:
효율적인 데이터 수집: 컨슈머가 대량의 데이터를 요청할 때, 지정된 데이터 양이 확보될 때까지 대기함으로써 네트워크 자원을 절약할 수 있습니다. 데이터의 안정성 보장: 데이터를 모두 수집한 후 일괄적으로 응답함으로써 안정적인 데이터 전송을 보장합니다. Purgatory의 이점 Kafka의 Purgatory 시스템은 메시지 복제 및 데이터 수집 시점을 제어할 수 있어, 높은 데이터 일관성과 전송 효율성을 유지하는 데 중요한 역할을 합니다. 또한, 이 구조 덕분에 Kafka는 대규모 데이터 스트림을 처리할 때 안정성과 성능을 유지할 수 있습니다.
댓글남기기