Iceberg와 MinIO를 사용한 레이크하우스 아키텍처
iceberg
apache iceberg는 데이터 세계를 강타한 것 같습니다. 처음에 Ryan Blue가 Netflix에서 인큐베이팅한 이 프로젝트는 결국 아파치 소프트웨어 재단으로 옮겨져 현재에 이르고 있습니다. 그 핵심은 대규모 분석 데이터 세트(수백 TB에서 수백 PB에 이르는)를 위한 오픈 테이블 형식입니다.
여러 엔진과 호환되는 형식입니다. 즉, Spark, Trino, Flink, Presto, Hive, Impala가 모두 데이터 집합에서 독립적으로 동시에 작동할 수 있다는 뜻입니다. 데이터 분석의 공용어인 SQL은 물론, 전체 스키마 진화, 숨겨진 파티셔닝, 시간 이동, 롤백 및 데이터 압축과 같은 주요 기능도 지원합니다.
이 게시물에서는 Iceberg와 MinIO가 어떻게 서로를 보완하는지, 그리고 다양한 분석 프레임워크(Spark, Flink, Trino, Dremio, Snowflake)가 이 두 가지를 어떻게 활용할 수 있는지에 대해 중점적으로 설명합니다.
배경
아파치 하이브는 당시에는 큰 진전을 이루었지만, 분석 애플리케이션이 점점 더 많아지고 다양해지고 정교해짐에 따라 궁극적으로 균열이 보이기 시작했습니다.
성능을 달성하기 위해서는 데이터가 디렉터리에 남아 있어야 하고 이러한 디렉터리를 지속적으로 관리해야 했습니다.
그 결과 디렉터리 데이터베이스를 구축하게 되었습니다.
이렇게 하면 데이터가 어디에 있느냐는 문제는 해결되었지만, 해당 테이블의 상태가 두 곳(디렉터리 데이터베이스와 파일 시스템)에 존재하게 되는 문제가 발생했습니다.
이로 인해 할 수 있는 작업과 유연성이 제한되었으며, 특히 변경 사항과 관련하여 한 번의 작업으로 두 곳 모두에서 보장할 수 없는 변경 사항이 발생했습니다.
다년간에 걸친 대량의 데이터가 날짜별로 분할되어 있다고 상상해 보세요. 연도가 월과 주 단위로 분할되고, 주 단위가 일 단위로 분할되고, 일 단위가 시간 단위로 분할되는 식으로 분할되면 디렉토리 목록이 폭발적으로 증가합니다. Hive 메타스토어(HMS)는 트랜잭션 RDBMS입니다. 파일 시스템(HDFS)은 비트랜잭션입니다. 파티션 정보가 변경되면 파티션 저장소와 파일 시스템을 모두 다시 만들어야 합니다.
이 문제는 지속 가능하지 않았고 아무리 패치를 적용해도 내재된 문제를 해결할 수 없었습니다. 실제로 데이터 증가에 따라 문제는 더욱 가속화되고 있었습니다.
최신 오픈 테이블 형식의 목표
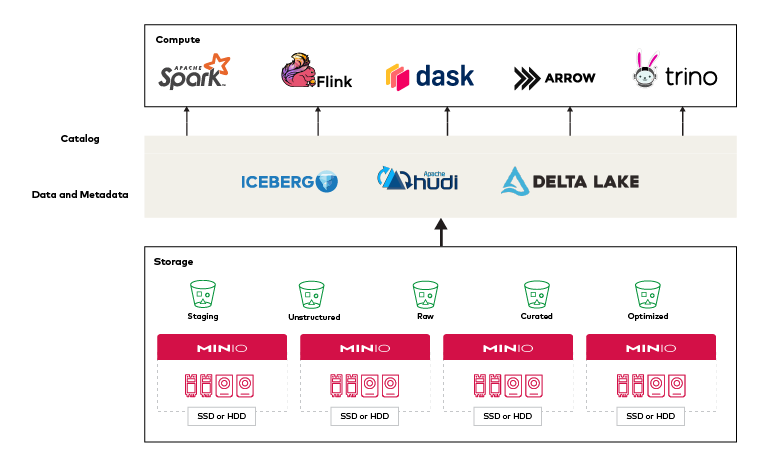
데이터 레이크하우스 아키텍처의 핵심 판매 포인트 중 하나는 여러 분석 엔진과 프레임워크를 지원한다는 점입니다. 예를 들어, ELT(추출, 로드, 변환)와 ETL(추출, 변환, 로드)을 모두 지원해야 합니다. 비즈니스 인텔리전스, 비즈니스 분석, AI/ML 유형의 워크로드를 지원해야 합니다. 안전하고 예측 가능한 방식으로 동일한 테이블 세트와 성공적으로 인터페이스해야 합니다. 즉, Spark, Flink, Trino, Arrow, Dask와 같은 여러 엔진이 모두 어떤 식으로든 일관된 아키텍처로 연결되어야 합니다.
각 엔진이 성공할 수 있도록 지원하면서 데이터를 효율적으로 저장하는 다중 엔진 플랫폼은 분석 업계가 갈망해 온 것이며, Iceberg 및 Data Lakehouse 아키텍처가 제공하는 것입니다.
데이터를 안정적으로 업데이트하면서 여러 엔진을 사용하는 것은 쉬운 일이 아니며 많은 어려움이 있습니다. 하지만 신뢰할 수 있는 업데이트를 제공하는 두세 가지 형식이 있는 지금도 여전히 많은 혼란이 있고 이 영역에 문제가 있습니다.
Apache Iceberg to the Rescue
Apache Iceberg는 처음부터 오픈 테이블 형식을 구현하기 위해 위에서 언급한 대부분의 과제와 목표를 기본으로 설계되었습니다.
다음과 같은 과제를 해결합니다:
- 유연한 컴퓨팅
데이터를 이동하지 않고 여러 엔진이 원활하게 작동해야 합니다.
배치, 스트리밍, 애드혹 작업 지원
JVM 프레임워크뿐 아니라 다양한 언어의 코드 지원 - SQL 웨어하우스 동작
CRUD 작업을 안정적으로 수행할 수 있는 SQL 테이블을 사용한 트랜잭션의 안정적 수행
실제 테이블에서 우려 사항을 분리하여 분리된 정보 제공
Apache Hive와 달리 Apache Iceberg는 오브젝트 스토리지에 레코드를 보관합니다. Iceberg를 사용하면 여러 엔진에서 SQL 동작을 활용할 수 있으며, 대규모 테이블을 위해 설계되었습니다. 단일 테이블에 수십 페타바이트의 데이터가 포함될 수 있는 프로덕션 환경에서는 이 점이 매우 중요합니다. 테이블 메타데이터를 선별하기 위해 분산된 SQL 엔진을 사용할 필요 없이 단일 노드에서 멀티 페타바이트 테이블도 읽을 수 있습니다.

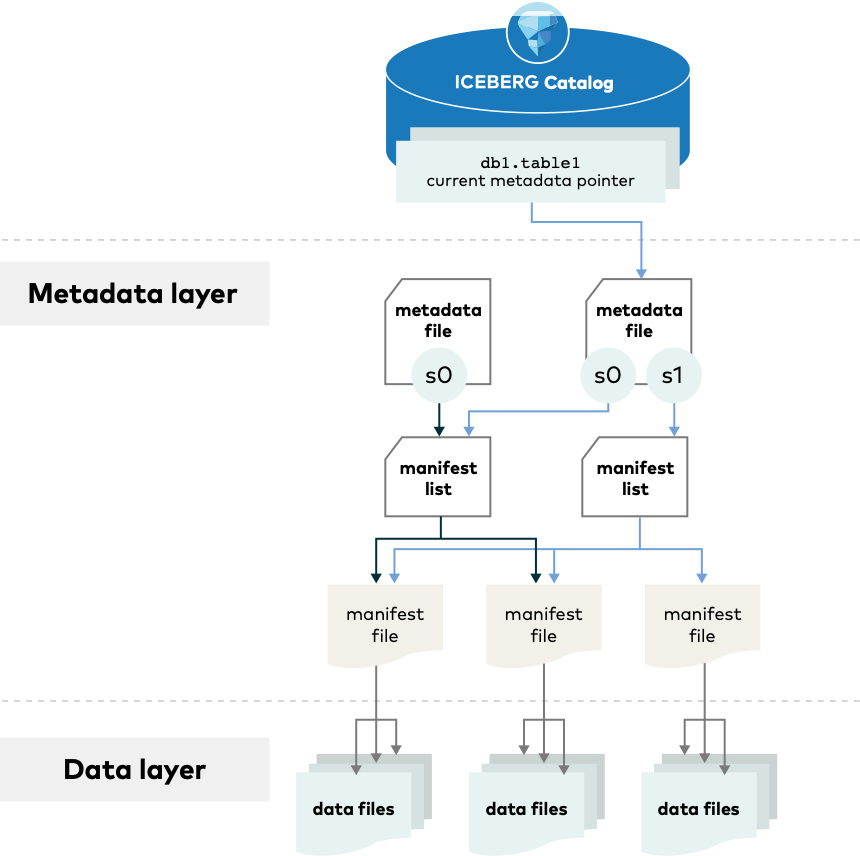
Source: https://iceberg.apache.org/spec/
Iceberg FileIO 이해
FileIO는 핵심 Iceberg 라이브러리와 기본 스토리지 사이의 인터페이스입니다. FileIO는 분산 컴퓨팅과 스토리지가 분리되어 있는 세상에서 Iceberg가 작동하기 위한 방법으로 만들어졌습니다. 레거시 Hadoop 에코시스템은 계층적 경로 지정과 파티션 구조를 필요로 하는데, 이는 실제로는 객체 스토리지 세계에서 속도와 확장성을 달성하는 데 사용되는 방법과는 정반대입니다.
Hadoop과 Hive는 고성능의 확장 가능한 클라우드 네이티브 오브젝트 스토리지에 대한 반(反)패턴입니다. S3 API를 사용해 MinIO와 상호 작용하는 데이터 레이크 애플리케이션은 수백만 또는 수십억 개의 개체에 대해 초당 수천 개의 트랜잭션으로 쉽게 확장할 수 있습니다. 여러 개의 동시 요청을 병렬로 처리하여 읽기 및 쓰기 성능을 향상시킬 수 있습니다. 접두사(첫 번째 문자로 시작하는 개체 이름의 하위 집합인 문자열)를 버킷에 추가한 다음 병렬 작업을 작성하여 각각 접두사당 연결을 열면 됩니다.
이와는 대조적으로, Iceberg는 오브젝트 스토리지를 사용하여 물리적 스토리지로부터 완전히 추상화되어 실행되도록 설계되었습니다. 모든 위치는 메타데이터에 정의된 대로 “명시적이고, 불변하며, 절대적”입니다. Iceberg는 참조 디렉터리의 번거로움 없이 테이블의 전체 상태를 추적합니다. 메타데이터를 사용해 테이블을 찾는 것이 S3 API를 사용해 전체 계층 구조를 나열하는 것보다 훨씬 빠릅니다. 커밋은 메타데이터 테이블에 새 항목을 추가하기만 하면 되므로 이름을 바꿀 필요가 없습니다.
FileIO API는 계획 및 커밋 단계에서 메타데이터 작업을 수행합니다. 작업은 FileIO를 사용하여 기본 데이터 파일을 읽고 쓰며, 이러한 파일의 위치는 커밋 중에 테이블 메타데이터에 포함됩니다. 엔진이 이 작업을 수행하는 정확한 방법은 FileIO의 구현에 따라 다릅니다. 레거시 환경의 경우, HadoopFileIO는 기존 Hadoop 파일 시스템 구현과 Iceberg 내의 FileIO API 사이의 어댑터 계층 역할을 합니다.
여기서는 네이티브 S3 구현인 S3FileIO에 초점을 맞추겠습니다. 클라우드 네이티브 레이크하우스를 구축할 때 Hadoop 크루프트를 가지고 다닐 필요가 없습니다. Iceberg FileIO: 클라우드 네이티브 테이블에 따르면, 네이티브 S3 구현의 장점은 다음과 같습니다:
컨트랙트 동작: Hadoop 파일 시스템 구현은 엄격한 컨트랙트 동작으로 인해 추가 요청(존재 확인, 디렉터리 및 경로 충돌 해제)이 발생하여 오버헤드와 복잡성이 추가됩니다. Iceberg는 완전히 주소 지정이 가능한 고유 경로를 사용하므로 추가적인 복잡성을 피할 수 있습니다.
최적화된 업로드: S3FileIO는 데이터를 점진적으로 업로드하여 대용량 작업의 디스크 소비를 최소화하고 출력을 위해 여러 파일이 열려 있을 때 낮은 메모리 소비를 유지함으로써 스토리지/메모리에 최적화합니다.
S3 클라이언트 사용자 지정: 클라이언트는 최신 주요 AWS SDK 버전(v2)을 사용하며, 사용자가 S3(모든 S3 API 호환 엔드포인트 포함)에서 사용할 수 있도록 클라이언트를 완전히 사용자 지정할 수 있습니다.
직렬화 성능: HadoopFileIO로 작업을 처리하려면 Hadoop 구성의 직렬화가 필요한데, 이 직렬화는 상당히 방대하며, 성능이 저하된 경우 처리 속도가 느려지고 처리되는 데이터보다 더 많은 오버헤드를 초래할 수 있습니다.
종속성 감소: Hadoop 파일 시스템 구현은 대규모 종속성 트리를 도입하고 구현을 간소화하여 전반적인 패키징 복잡성을 줄입니다.
Iceberg는 0.11.0 이후의 모든 버전에 대해 Spark 및 Flink 런타임과 함께 번들로 제공되는 iceberg-aws 모듈을 통해 다양한 AWS 서비스와의 통합을 제공합니다.
Iceberg를 사용하면 S3FileIO를 통해 S3에 데이터를 쓸 수 있습니다. S3FileIO를 사용할 때 카탈로그는 io-impl 카탈로그 속성을 사용하여 S3 API를 사용하도록 구성됩니다. S3FileIO는 최적화된 보안(S3 액세스 제어 목록, 세 가지 S3 서버 측 암호화 모드) 및 성능(프로그레시브 멀티파트 업로드)을 위해 최신 S3 기능을 채택하고 있으므로 개체 스토리지 사용 사례에 권장됩니다.
Iceberg and MinIO Tutorial
현재 Spark는 Iceberg 작업을 위한 가장 풍부한 기능을 갖춘 컴퓨팅 엔진이므로, 이 튜토리얼에서는 Spark와 Spark-SQL을 사용하여 Iceberg의 개념과 기능을 이해하는 데 중점을 둡니다. redhat 8.x에서 Java, 카탈로그 또는 메타데이터 포인터로 PostgreSQL, Spark 및 MinIO를 설치하고 구성하는 동시에 Java 종속성을 신중하게 다운로드하고 구성합니다. 그런 다음 Spark-SQL을 실행하여 테이블을 생성, 채우기, 쿼리 및 수정합니다. 또한 스키마 진화, 숨겨진 파티션 작업, 시간 여행 및 롤백 등 Iceberg로 할 수 있는 몇 가지 멋진 기능도 살펴봅니다. 각 단계가 끝나면 MinIO에 있는 Iceberg 버킷의 스크린샷이 포함되어 있어 백그라운드에서 어떤 일이 벌어지고 있는지 확인할 수 있습니다.
Prerequisites
minio standalone docker-compose를 이용하여 minio를 설치합니다.
data 폴더생성
mkdir data
version: '3'
services:
minio:
image: minio/minio
command: server /data --console-address ":9001"
container_name: minio
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio1234@
restart: always
shm_size: '1gb'
ports:
- "9000:9000"
- "9001:9001"
volumes:
- ./data:/data
minio 설치
docker-compose up -d
웹브라우저를 통해 http:/myserver:9000 또는 자신의 pc인 경우 http://localhost:9000 으로 접속하여 console login을 확인합니다. minio consle에서 Access Keys 메뉴에서 access key를 생성합니다. Access Keys > Create access key
MinIO 클라이언트를 사용하여 별칭을 설정하고 Iceberg용 버킷을 생성하세요.
docker exec -it minio bash
mc alias set minio http://myserver:9000 myaccess-key my-secret-key
Added `minio` successfully.
mc mb minio/iceberg
Bucket created successfully `minio/iceberg`.
Hadoop, AWS S3, JDBC와 같은 다양한 기능을 사용하려면 필요한 JAR(Java 아카이브)을 사용하도록 Spark를 다운로드하고 구성해야 합니다. 또한 필요한 각 JAR과 구성 파일의 올바른 버전이 PATH 및 CLASSPATH에 있어야 합니다.
RHEL 8에 OpenJDK를 설치하려면 먼저 그림과 같이 dnf 명령을 사용하여 시스템 패키지를 업데이트합니다.
# dnf update
그런 다음 다음 명령을 사용하여 OpenJDK 8 및 11을 설치합니다.
# dnf install java-1.8.0-openjdk-devel #install JDK 8
# dnf install java-11-openjdk-devel #install JDK 11
설치 프로세스가 완료되면 다음 명령을 사용하여 설치된 Java 버전을 확인할 수 있습니다.
# java -version
## PostgreSQL 구성하기
version: '3.5'
services:
postgres:
container_name: postgres
image: postgres:latest
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: admin1234
PGDATA: /data/postgres
volumes:
- postgres-db:/data/postgres
ports:
- "5432:5432"
volumes:
postgres-db:
driver: local
postgres 설치
docker-compose up -d
docker exec -it postgres bash
pgsql -U postgre
create user icebergcat with PASSWORD 'minio' CREATEDB;
create database icebergcat owner icebergcat ENCODING 'UTF-8';
ALTER USER icebergcat WITH SUPERUSER;
CREATE SCHEMA icebergcat;
\q
psql -U icebergcat -d icebergcat -W -h 127.0.0.1
\q
Download, extract, and move Apache Spark
$ wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz
$ tar zxvf spark-3.2.4-bin-hadoop3.2.tgz
$ sudo mv spark-3.2.4-bin-hadoop3.2/ /opt/spark
.bashrc에 다음을 추가하고 셸을 다시 시작하여 변경 사항을 적용하여 Spark 환경을 설정합니다.
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
bash -l
다음 .jar 파일이 필요합니다. .jar 파일을 다운로드하여 스파크 머신의 필요한 위치(예: /opt/spark/jars)에 복사합니다.
S3 프로토콜을 지원하려면 aws-java-sdk-bundle/1.11.901.jar(또는 그 이상)이 필요합니다.
wget https://repo1.maven.org/maven2/software/amazon/awssdk/bundle/2.17.230/bundle-2.17.230.jar
mv bundle-2.17.230.jar /opt/spark/jars/
Download iceberg-spark-runtime-3.2_2.12.jar .
wget https://repo.maven.apache.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.1_2.12/0.13.2/iceberg-spark-runtime-3.1_2.12-0.13.2.jar
mv iceberg-spark-runtime-3.1_2.12-0.13.2.jar /opt/spark/jars/
Start Spark
Spark 독립 실행형 마스터 서버 시작
# spark-master : /etc/hosts
MASTER=spark://spark-master:7077
start-master.sh
# Start a Spark worker process
start-slave.sh ${MASTER}
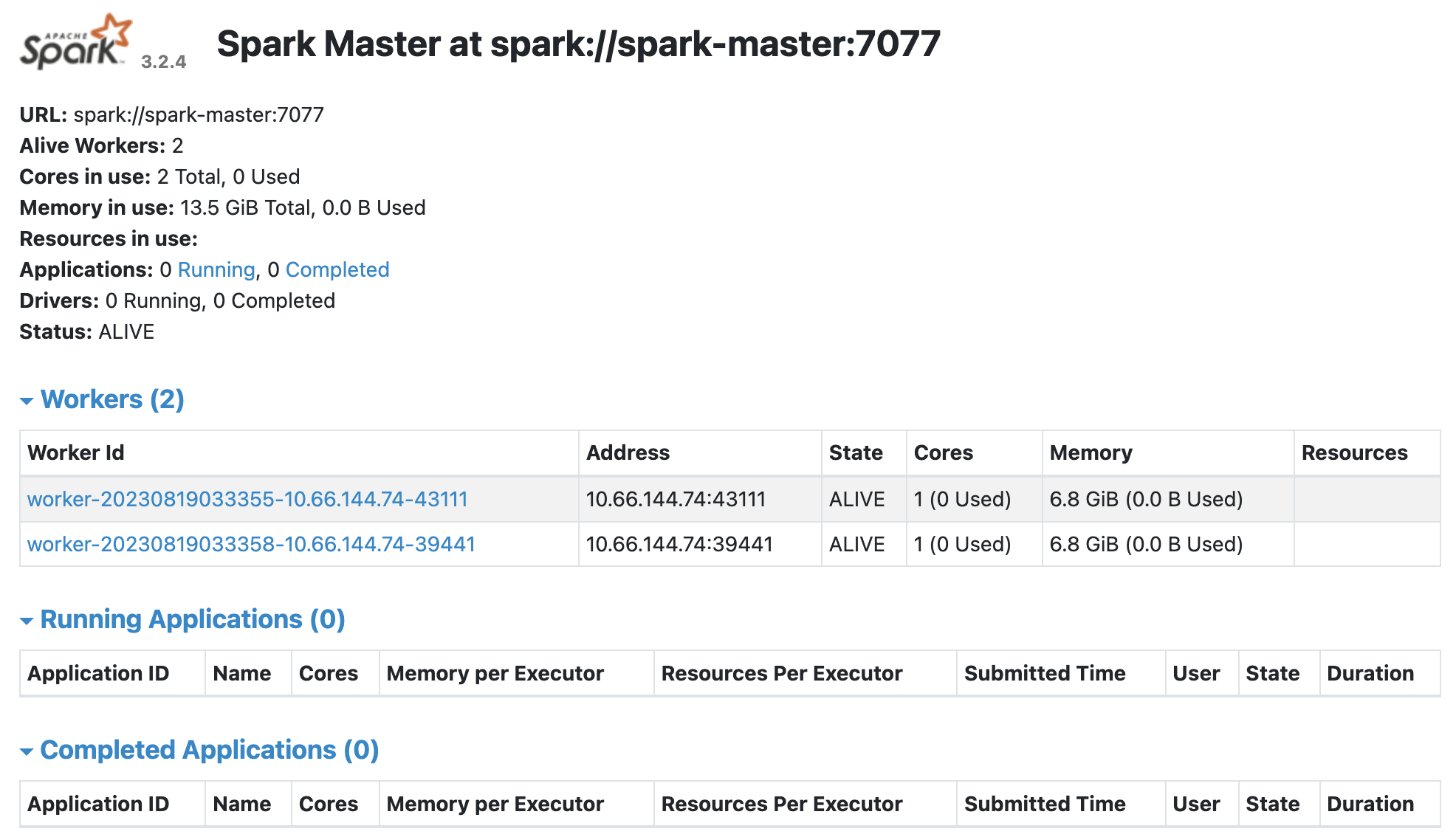
Spark is alive at spark://
Start a Spark worker process
Spark-SQL and Iceberg
이 구성에 대한 몇 가지 중요한 참고 사항
- JDBC를 사용하여 내부 IP 주소에서 PostgreSQL에 연결하고 메타데이터에 icebergcat 테이블을 사용하는 카탈로그 my_catalog를 선언합니다.
- 그런 다음 웨어하우스 위치를 앞서 생성한 MinIO 버킷으로 설정하고 S3FileIO를 사용하여 액세스하도록 Iceberg를 구성했습니다.
start-sparksql
# start-env.sh
DEPENDENCIES=''
export AWS_ACCESS_KEY_ID=flsfYX3esSeyCrOAm45k
export AWS_SECRET_ACCESS_KEY=PCoVFDxrVIt1zAwzNIgZAOklsrnlF4q85ZA2uJ9w
export AWS_S3_ENDPOINT=119.81.34.106:9000
export AWS_REGION=us-east-1
export MINIO_REGION=us-east-1
export DEPENDENCIES="org.apache.iceberg:iceberg-spark-runtime-3.2_2.13:1.3.1"
export AWS_SDK_VERSION=2.17.230
export AWS_MAVEN_GROUP=software.amazon.awssdk
export AWS_PACKAGES=(
"bundle"
"url-connection-client"
)
for pkg in "${AWS_PACKAGES[@]}"; do
echo $pkg
export DEPENDENCIES+=",$AWS_MAVEN_GROUP:$pkg:$AWS_SDK_VERSION"
done
# start-sparksql.sh
spark-sql --packages $DEPENDENCIES \
--conf spark.sql.cli.print.header=true \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.jdbc.JdbcCatalog \
--conf spark.sql.catalog.my_catalog.jdbc.verifyServerCertificate=true \
--conf spark.sql.catalog.my_catalog.uri=jdbc:postgresql://119.81.34.106:5432/icebergcat \
--conf spark.sql.catalog.my_catalog.jdbc.user=icebergcat \
--conf spark.sql.catalog.my_catalog.jdbc.password=minio \
--conf spark.sql.catalog.my_catalog.warehouse=s3://iceberg \
--conf spark.sql.catalog.my_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO \
--conf spark.sql.catalog.my_catalog.s3.endpoint=http://127.0.0.1:9000 \
--conf spark.sql.catalog.sparkcatalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.defaultCatalog=my_catalog \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=/home/nexweb/iceicedata/spark-events \
--conf spark.history.fs.logDirectory= /home/nexweb/iceicedata/spark-events \
--conf spark.sql.catalogImplementation=in-memory
Creating a Table
CREATE TABLE my_catalog.my_table (
id bigint,
data string,
category string)
USING iceberg
LOCATION 's3://iceberg'
PARTITIONED BY (category);
다음은 Iceberg가 S3FileIO를 통해 제공하는 엄청난 성능 향상입니다. 기존 Hive 스토리지 레이아웃을 S3와 함께 사용할 때 객체 접두사에 따라 요청을 스로틀링하는 바람에 성능이 느려져 어려움을 겪었던 사용자들에게 큰 도움이 될 것입니다. AWS S3에서 파티셔닝된 Athena/Hive 테이블을 생성하는 데 30~60분이 소요된다는 것은 잘 알려진 사실입니다. Iceberg는 기본적으로 Hive 스토리지 레이아웃을 사용하지만, ObjectStoreLocationProvider를 사용하도록 전환할 수 있습니다. ObjectStoreLocationProvider를 사용하면 저장된 각 파일에 대해 결정론적 해시가 생성되며, 이 해시는 write.data.경로 바로 뒤에 추가됩니다. 이렇게 하면 S3 호환 오브젝트 스토리지에 쓰여진 파일이 S3 버킷의 여러 접두사에 균등하게 분산되어 S3 관련 IO 작업의 스로틀링을 최소화하고 처리량을 최대화할 수 있습니다. ObjectStoreLocationProvider를 사용할 때, Iceberg 테이블 전체에 걸쳐 공유되고 짧은 write.data.경로를 사용하면 성능이 향상됩니다. 이 외에도 Iceberg에서는 Hive에 비해 성능과 안정성을 개선하기 위해 훨씬 더 많은 작업이 수행되었습니다.
다음으로, 모의 데이터를 삽입하고 Iceberg가 MinIO에 저장하는 파일을 살펴보겠습니다. 이제 Iceberg 버킷 내부에 my_table/metadata 및 my_table/data 접두사가 있습니다.
INSERT INTO my_catalog.my_table VALUES (1, 'a', "music"), (2, 'b', "music"), (3, 'c', "video");
Query 실행
spark-sql> SELECT count(1) as count, data
FROM my_catalog.my_table
GROUP BY data;
1 a
1 b
1 c
Time taken: 9.715 seconds, Fetched 3 row(s)
spark-sql>
aws-cli 설치
pip3 install awscli --upgrade --user
Begin AWS CLI configuration
aws configure
댓글남기기